This issue tracker has been migrated to GitHub,
and is currently read-only.
For more information,
see the GitHub FAQs in the Python's Developer Guide.
Created on 2002-05-25 01:07 by ccraig, last changed 2022-04-10 16:05 by admin. This issue is now closed.
| Files | ||||
|---|---|---|---|---|
| File name | Uploaded | Description | Edit | |
| k_mul.patch | ccraig, 2002-05-25 01:07 | patch | ||
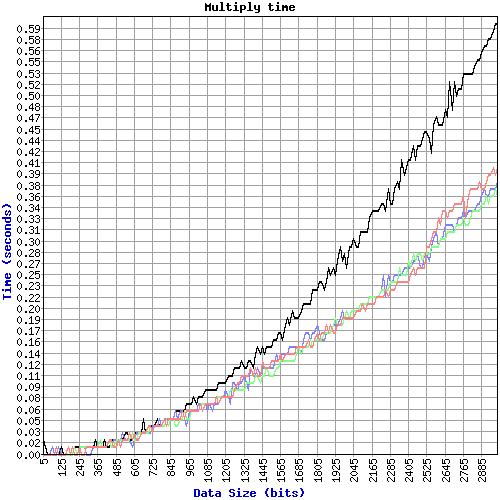
| output.jpg | ccraig, 2002-05-25 16:16 | Timing graph | ||
| k_mul2.patch | ccraig, 2002-05-25 23:41 | patch, take 2 (splits on larger number) | ||
| k_mul3.patch | ccraig, 2002-07-09 22:43 | patch, take 3 (cleaned up, better comments) | ||

{kind=link}
| History | |||
|---|---|---|---|
| Date | User | Action | Args |
| 2022-04-10 16:05:21 | admin | set | github: 36647 |
| 2002-05-25 01:07:03 | ccraig | create | |