Issue45105
This issue tracker has been migrated to GitHub,
and is currently read-only.
For more information,
see the GitHub FAQs in the Python's Developer Guide.
Created on 2021-09-05 11:12 by maxbachmann, last changed 2022-04-11 14:59 by admin.
| Files | ||||
|---|---|---|---|---|
| File name | Uploaded | Description | Edit | |
| selection.png | steven.daprano, 2021-09-05 13:08 | |||
{kind=link}
| Messages (12) | |||
|---|---|---|---|
| msg401078 - (view) | Author: Max Bachmann (maxbachmann) * | Date: 2021-09-05 11:12 | |
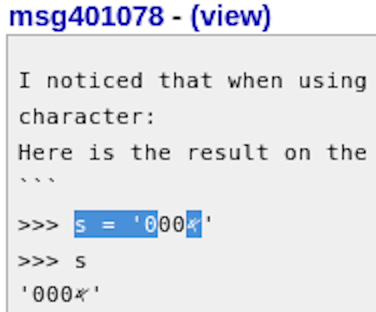
I noticed that when using the Unicode character \U00010900 when inserting the character as character: Here is the result on the Python console both for 3.6 and 3.9: ``` >>> s = '0𐤀00' >>> s '0𐤀00' >>> ls = list(s) >>> ls ['0', '𐤀', '0', '0'] >>> s[0] '0' >>> s[1] '𐤀' >>> s[2] '0' >>> s[3] '0' >>> ls[0] '0' >>> ls[1] '𐤀' >>> ls[2] '0' >>> ls[3] '0' ``` It appears that for some reason in this specific case the character is actually stored in a different position that shown when printing the complete string. Note that the string is already behaving strange when marking it in the console. When marking the special character it directly highlights the last 3 characters (probably because it already thinks this character is in the second position). The same behavior does not occur when directly using the unicode point ``` >>> s='000\U00010900' >>> s '000𐤀' >>> s[0] '0' >>> s[1] '0' >>> s[2] '0' >>> s[3] '𐤀' ``` This was tested using the following Python versions: ``` Python 3.6.0 (default, Dec 29 2020, 02:18:14) [GCC 10.2.1 20201125 (Red Hat 10.2.1-9)] on linux Python 3.9.6 (default, Jul 16 2021, 00:00:00) [GCC 11.1.1 20210531 (Red Hat 11.1.1-3)] on linux ``` on Fedora 34 |
|||
| msg401079 - (view) | Author: Max Bachmann (maxbachmann) * | Date: 2021-09-05 11:18 | |
This is the result of copy pasting example posted above on windows using ``` Python 3.7.8 (tags/v3.7.8:4b47a5b6ba, Jun 28 2020, 08:53:46) [MSC v.1916 64 bit (AMD64)] on win32 ``` which appears to run into similar problems: ``` >>> s = '0��00' >>> s '0𐤀00' >>> ls = list(s) >>> ls ['0', '𐤀', '0', '0'] >>> s[0] '0' >>> s[1] '𐤀' ``` |
|||
| msg401082 - (view) | Author: Eryk Sun (eryksun) *  |
Date: 2021-09-05 12:53 | |
AFAICT, there is no bug here. It's just confusing how Unicode right-to-left characters in the repr() can modify how it's displayed in the console/terminal. Use the ascii() representation to avoid the problem.
> The same behavior does not occur when directly using the unicode point
> ```
> >>> s='000\U00010900'
The original string has the Phoenician right-to-left character at index 1, not at index 3. The "0" number characters in the original have weak directionality when displayed. You can see the reversal with a numeric sequence that's separated by spaces. For example:
s = '123\U00010900456'
>>> print(*s, sep='\n')
1
2
3
𐤀
4
5
6
>>> print(*s)
1 2 3 𐤀 4 5 6
Latin letters have left-to-right directionality. For example:
>>> s = '123\U00010900abc'
>>> print(*s)
1 2 3 𐤀 a b c
You can check the bidirectional property [1] using the unicodedata module:
>>> import unicodedata as ud
>>> ud.bidirectional('\U00010900')
'R'
>>> ud.bidirectional('0')
'EN'
>>> ud.bidirectional('a')
'L'
---
[1] https://en.wikipedia.org/wiki/Unicode_character_property#Bidirectional_writing
|
|||
| msg401083 - (view) | Author: Steven D'Aprano (steven.daprano) *  |
Date: 2021-09-05 13:08 | |
I'm afraid I cannot reproduce the problem. >>> s = '000𐤀' # \U00010900 >>> s '000𐤀' >>> s[0] '0' >>> s[1] '0' >>> s[2] '0' >>> s[3] '𐤀' >>> list(s) ['0', '0', '0', '𐤀'] That is using Python 3.9 in the xfce4-terminal. Which xterm are you using? I am very confident that it is a bug in some external software, possibly the xterm, possibly the browser or other application where you copied the PHOENICIAN LETTER ALF character from in the first place. It looks like it is related to mishandling of the Right-To-Left character: >>> unicodedata.bidirectional(s[3]) 'R' Using Firefox, when I attempt to select the text s = '000...' in Max's initial message with the mouse, the selection highlighting jumps around. See the screenshot attached. (selection.png) Depending on how I copy the text, sometimes I get '000 ALF' and sometimes '0 ALF 00' which hints that something is getting confused by the RTL character, possibly the browser, possible the copy/paste clipboard, possibly the terminal. But regardless, I cannot replicate the behaviour you show where list(s) is different from indexing the characters one by one. It is very common for applications to mishandle mixed RTL and LTR characters, and that can have all sorts of odd display and copy/paste issues. |
|||
| msg401084 - (view) | Author: Steven D'Aprano (steven.daprano) * |
Date: 2021-09-05 13:15 | |
Eryk Sun said:
> The original string has the Phoenician right-to-left character at index 1, not at index 3.
I think you may be mistaken. In Max's original post, he has
s = '000X'
where the X is actually the Phoenician ALF character. At least that is how it is displayed in my browser.
(But note that in the Windows terminal, Max has '0X00' instead.)
Max's demonstration code shows a discrepancy between extracting the chars one by one using indexing, and with list. Simulating his error:
s = '000X' # X is actually ALF
list(s)
# --> returns [0 0 0 X]
[s[i] for i in range(4)] # indexing each char one at a time
# --> returns [0 X 0 0]
I have not yet been able to replicate that reported behaviour.
I agree totally with Eryk Sun that this is probably not a Python bug. He thinks it is displaying the correct behaviour. I think it is probably a browser or xterm bug.
But unless someone can replicate the mismatch between list and indexing, I doubt it is something we can do anything about.
|
|||
| msg401086 - (view) | Author: Eryk Sun (eryksun) * |
Date: 2021-09-05 13:56 | |
> I think you may be mistaken. In Max's original post, he has > s = '000X' It displays that way for me under Firefox in Linux, but what's really there when I copy it from Firefox is '0\U0001090000', which matches the result Max gets for individual index operations such as s[1]. The "0" characters following the R-T-L character have weak directionality. So the string displays the same as "000\U00010900". If you print with spaces and use a number sequence, the substring starting with the R-T-L character should display reversed, i.e. print(*'123\U00010900456') should display the same as print(*'123654\U00010900'). But "abc" in print(*'123\U00010900abc') should not display reversed since it has L-T-R directionality. |
|||
| msg401088 - (view) | Author: Max Bachmann (maxbachmann) * | Date: 2021-09-05 14:51 | |
> That is using Python 3.9 in the xfce4-terminal. Which xterm are you using?
This was in the default gnome terminal that is pre-installed on Fedora 34 and on windows I directly opened the Python Terminal. I just installed xfce4-terminal on my Fedora 34 machine which has exactly the same behavior for me that I had in the gnome terminal.
> But regardless, I cannot replicate the behavior you show where list(s) is different from indexing the characters one by one.
That is what surprised me the most. I just ran into this because this was somehow generated when fuzz testing my code using hypothesis (which uncovered an unrelated bug in my application). However I was quite confused by the character order when debugging it.
My original case was:
```
s1='00ĀĀĀĀ'
s2='9010𐤀000\x8dÀĀĀĀ222Ā'
parts = [s2[max(0, i) : min(len(s2), i+len(s1))] for i in range(-len(s1), len(s2))]
for part in parts:
print(list(part))
```
which produced
```
[]
['9']
['9', '0']
['9', '0', '1']
['9', '0', '1', '0']
['9', '0', '1', '0', '𐤀']
['9', '0', '1', '0', '𐤀', '0']
['0', '1', '0', '𐤀', '0', '0']
['1', '0', '𐤀', '0', '0', '0']
['0', '𐤀', '0', '0', '0', '\x8d']
['𐤀', '0', '0', '0', '\x8d', 'À']
['0', '0', '0', '\x8d', 'À', 'Ā']
['0', '0', '\x8d', 'À', 'Ā', 'Ā']
['0', '\x8d', 'À', 'Ā', 'Ā', 'Ā']
['\x8d', 'À', 'Ā', 'Ā', 'Ā', '2']
['À', 'Ā', 'Ā', 'Ā', '2', '2']
['Ā', 'Ā', 'Ā', '2', '2', '2']
['Ā', 'Ā', '2', '2', '2', 'Ā']
['Ā', '2', '2', '2', 'Ā']
['2', '2', '2', 'Ā']
['2', '2', 'Ā']
['2', 'Ā']
['ĀÀ]
```
which has a missing single quote:
- ['ĀÀ]
changing direction of characters including commas:
- ['1', '0', '𐤀', '0', '0', '0']
changing direction back:
- ['𐤀', '0', '0', '0', '\x8d', 'À']
> AFAICT, there is no bug here. It's just confusing how Unicode right-to-left characters in the repr() can modify how it's displayed in the console/terminal.
Yes it appears the same confusion occurs in other applications like Firefox and VS Code.
Thanks at @eryksun and @steven.daprano for testing and telling me about Bidirectional writing in Unicode (The more I know about Unicode the more it scares me)
|
|||
| msg401090 - (view) | Author: Steven D'Aprano (steven.daprano) * |
Date: 2021-09-05 15:53 | |
> what's really there when I copy it from Firefox is '0\U0001090000',
> which matches the result Max gets for individual index operations such as s[1].
But *not* the result that Max got from calling list().
Can you reproduce that difference between indexing and list?
Also you say "what's really there", but what is your reasoning for that?
How do you know that Firefox is displaying the string wrongly, rather
than displaying it correctly and copying it to the clipboard wrongly?
When I look at the page source of the b.p.o page, I see:
<pre>I noticed that when using the Unicode character \U00010900 when
inserting the character as character:
Here is the result on the Python console both for 3.6 and 3.9:
```
>>> s = '000X'
again, with X standing in for the Phoenician ALF character. But when I
copy and paste it into my terminal, I see
>>> s = '0X00'
|
|||
| msg401092 - (view) | Author: Steven D'Aprano (steven.daprano) * |
Date: 2021-09-05 16:01 | |
Hmmm, digging deeper, I saved the page source code and opened it with hexdump. The relevant lines are: 00007780 60 60 0d 0a 26 67 74 3b 26 67 74 3b 26 67 74 3b |``..>>>| 00007790 20 73 20 3d 20 27 30 f0 90 a4 80 30 30 27 0d 0a | s = '0....00'..| which looks like Eryk Sun is correct, what is really there is '0X00' and Firefox just displays it in RTL order '000X'. Mystery solved :-) So now that only leaves the (unreproduced?) bug report of the difference in order between indexing and list(). Max, are you still certain that this difference exists? Can you replicate it with other strings, preferably with distinct characters? |
|||
| msg401095 - (view) | Author: Max Bachmann (maxbachmann) * | Date: 2021-09-05 16:32 | |
As far as a I understood this is caused by the same reason: ``` >>> s = '123\U00010900456' >>> s '123𐤀456' >>> list(s) ['1', '2', '3', '𐤀', '4', '5', '6'] # note that everything including the commas is mirrored until ] is reached >>> s[3] '𐤀' >>> list(s)[3] '𐤀' >>> ls = list(s) >>> ls[3] += 'a' >>> ls ['1', '2', '3', '𐤀a', '4', '5', '6'] ``` Which as far as I understood is the expected behavior when a right-to-left character is encountered. |
|||
| msg401656 - (view) | Author: Ronald Oussoren (ronaldoussoren) * |
Date: 2021-09-12 08:38 | |
@Steven: the difference between indexing and the repr of list() is also explained by Eryk's explanation. s = ... # (value from msg401078) for x in repr(list(s)): print(x) The output shows characters in the expected order. |
|||
| msg401658 - (view) | Author: Serhiy Storchaka (serhiy.storchaka) * |
Date: 2021-09-12 08:57 | |
We recently discussed the RTLO attack on Python sources (sorry, I don't remember on what resource) and decided that we should do something with this. I think this is a related issue. |
|||
| History | |||
|---|---|---|---|
| Date | User | Action | Args |
| 2022-04-11 14:59:49 | admin | set | github: 89268 |
| 2021-09-12 08:57:14 | serhiy.storchaka | set | messages: + msg401658 |
| 2021-09-12 08:38:45 | ronaldoussoren | set | nosy:
+ ronaldoussoren messages: + msg401656 |
| 2021-09-10 22:27:49 | terry.reedy | set | nosy:
+ serhiy.storchaka |
| 2021-09-06 16:40:21 | vstinner | set | nosy:
- vstinner |
| 2021-09-05 16:32:08 | maxbachmann | set | messages: + msg401095 |
| 2021-09-05 16:01:40 | steven.daprano | set | messages: + msg401092 |
| 2021-09-05 15:53:23 | steven.daprano | set | messages: + msg401090 |
| 2021-09-05 14:51:42 | maxbachmann | set | status: pending -> open messages: + msg401088 |
| 2021-09-05 13:57:48 | serhiy.storchaka | set | status: open -> pending |
| 2021-09-05 13:56:38 | eryksun | set | messages: + msg401086 |
| 2021-09-05 13:15:48 | steven.daprano | set | messages: + msg401084 |
| 2021-09-05 13:08:09 | steven.daprano | set | files:
+ selection.png nosy: + steven.daprano messages: + msg401083 |
| 2021-09-05 12:53:10 | eryksun | set | nosy:
+ eryksun messages: + msg401082 |
| 2021-09-05 11:18:39 | maxbachmann | set | messages: + msg401079 |
| 2021-09-05 11:12:09 | maxbachmann | create | |