Issue41972
This issue tracker has been migrated to GitHub,
and is currently read-only.
For more information,
see the GitHub FAQs in the Python's Developer Guide.
Created on 2020-10-07 23:31 by Zeturic, last changed 2022-04-11 14:59 by admin. This issue is now closed.
| Files | ||||
|---|---|---|---|---|
| File name | Uploaded | Description | Edit | |
| reproducer.py | Dennis Sweeney, 2020-10-08 11:06 | |||
| fastsearch.diff | tim.peters, 2020-10-09 14:56 | |||
| fastsearch.py | Dennis Sweeney, 2020-10-11 06:51 | Pure-python two-way string search algorithm translated from glibc | ||
| fastsearch.h | Dennis Sweeney, 2020-10-12 07:00 | Drop-in replacement for Objects/stringlib/fastsearch.h using the two-way algorithm | ||
| bench_results.txt | Dennis Sweeney, 2020-10-12 23:50 | |||
| random_bench.py | Dennis Sweeney, 2020-10-12 23:55 | Test `str in str` on random words of a language with a Zipf distribution | ||
| bench_table.txt | Dennis Sweeney, 2020-10-13 21:42 | |||
| twoway-benchmark-results-2020-10-28.txt | taleinat, 2020-10-28 08:15 | |||
| Table of benchmarks on lengths.jpg | Dennis Sweeney, 2020-11-06 20:28 | |||
| length_benchmarks.txt | Dennis Sweeney, 2020-11-06 20:31 | |||
| twoway_demo.py | Dennis Sweeney, 2020-12-13 01:35 | Added Checkbox for using shift-table | ||
| comparison.jpg | Dennis Sweeney, 2021-01-17 22:56 | Benchmarks of Two-Way algorithm versus adaptive algorithm on Zipf benchmarks | ||
{kind=link}
{kind=link}
| Pull Requests | |||
|---|---|---|---|
| URL | Status | Linked | Edit |
| PR 22679 | closed | Dennis Sweeney, 2020-10-12 23:43 | |
| PR 22904 | merged | Dennis Sweeney, 2020-10-23 00:03 | |
| PR 24672 | merged | Dennis Sweeney, 2021-02-28 21:12 | |
| PR 27091 | merged | Dennis Sweeney, 2021-07-12 03:56 | |
| Messages (77) | |||
|---|---|---|---|
| msg378197 - (view) | Author: Kevin Mills (Zeturic) | Date: 2020-10-07 23:31 | |
Sorry for the vague title. I'm not sure how to succinctly describe this issue.
The following code:
```
with open("data.bin", "rb") as f:
data = f.read()
base = 15403807 * b'\xff'
longer = base + b'\xff'
print(data.find(base))
print(data.find(longer))
```
Always hangs on the second call to find.
It might complete eventually, but I've left it running and never seen it do so. Because of the structure of data.bin, it should find the same position as the first call to find.
The first call to find completes and prints near instantly, which makes the pathological performance of the second (which is only searching for one b"\xff" more than the first) even more mystifying.
I attempted to upload the data.bin file I was working with as an attachment here, but it failed multiple times. I assume it's too large for an attachment; it's a 32MiB file consisting only of 00 bytes and FF bytes.
Since I couldn't attach it, I uploaded it to a gist. I hope that's okay.
https://gist.github.com/Zeturic/7d0480a94352968c1fe92aa62e8adeaf
I wasn't able to trigger the pathological runtime behavior with other sequences of bytes, which is why I uploaded it in the first place. For example, if it is randomly generated, it doesn't trigger it.
I've verified that this happens on multiple versions of CPython (as well as PyPy) and on multiple computers / operating systems.
|
|||
| msg378209 - (view) | Author: Josh Rosenberg (josh.r) *  |
Date: 2020-10-08 03:12 | |
Can reproduce on Alpine Linux, with CPython 3.8.2 (running under WSLv2), so it's not just you. CPU usage is high; seems like it must be stuck in an infinite loop. |
|||
| msg378210 - (view) | Author: Tim Peters (tim.peters) *  |
Date: 2020-10-08 03:21 | |
Also reproduced on 64-bit Win10 with just-released 3.9.0. Note that string search tries to incorporate a number of tricks (pieces of Boyer-Moore, Sunday, etc) to speed searches. The "skip tables" here are probably computing a 0 by mistake. The file here contains only 2 distinct byte values, and the relatively huge string to search for has only 1, so there's plenty of opportunity for those tricks to get confused ;-) |
|||
| msg378221 - (view) | Author: Serhiy Storchaka (serhiy.storchaka) * |
Date: 2020-10-08 07:58 | |
What is the content of "data.bin"? How can we reproduce the issue? |
|||
| msg378222 - (view) | Author: Ammar Askar (ammar2) * |
Date: 2020-10-08 08:03 | |
It's available from the Github gist that Kevin posted. Here is a direct link that you can curl/wget: https://gist.github.com/Zeturic/7d0480a94352968c1fe92aa62e8adeaf/raw/6daebaabedaa903016810c2c04d0d1f0b1af1ed3/data.bin |
|||
| msg378225 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-08 09:09 | |
Adding some hasty printf-debugging to fastsearch.h, I see this:
>>> with open('data.bin', 'rb') as f:
... s = f.read()
...
>>> base = 15403807 * b'\xff'
>>> longer = base + b'\xff'
>>> base in s
Bloom has 0x00: 0
Bloom has 0xff: -2147483648
skip = 0
Checking bloom filter for next char 0x00... not found in pattern. Skipping a bunch.
Candidate at 15403808
True
>>> longer in s
Bloom has 0x00: No
Bloom has 0xff: Yes
skip = 0
Checking bloom filter for next char 0xff... found in pattern; increment by only one.
Candidate at 1
Candidate at 2
Candidate at 3
Candidate at 4
Candidate at 5
Candidate at 6
Candidate at 7
(...)
Trying the same base, I also get this:
>>> with open('data.bin', 'rb') as f:
... s = f.read()
...
>>> base = 15403807 * b'\xff'
>>> s1 = s[1:]
>>> base in s1
Bloom has 0x00: No
Bloom has 0xff: Yes
skip = 0
Checking bloom filter for next char 0xff... found in pattern; increment by only one.
Candidate at 1
Candidate at 2
Candidate at 3
Candidate at 4
Candidate at 5
Candidate at 6
Candidate at 7
(...)
So maybe part of the issue is just that the algorithm is getting particularly
unlucky regarding how the strings line up to start with.
The fact that "skip" is 0 in these cases seems to just be a limitation of the algorithm:
we only skip to line up the second-to-last occurrence of the last character,
but with these strings, that's just the second-to-last character.
Computing the entire Boyer-Moore table would be better in cases like these, but
that would require dynamic memory allocation (length of pattern) which I think is why it is avoided.
|
|||
| msg378229 - (view) | Author: STINNER Victor (vstinner) * |
Date: 2020-10-08 09:59 | |
Does the code really hang? Or does it complete if you wait for an infinite amount of time? I understand that your concern is that bytes.find() is inefficient for a very specific pattern. |
|||
| msg378233 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-08 11:06 | |
Indeed, this is just a very unlucky case.
>>> n = len(longer)
>>> from collections import Counter
>>> Counter(s[:n])
Counter({0: 9056995, 255: 6346813})
>>> s[n-30:n+30].replace(b'\x00', b'.').replace(b'\xff', b'@')
b'..............................@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@'
>>> Counter(s[n:])
Counter({255: 18150624})
When checking "base", we're in this situation
pattern: @@@@@@@@
string: .........@@@@@@@@
Algorithm says: ^ these last characters don't match.
^ this next character is not in the pattern
Therefore, skip ahead a bunch:
pattern: @@@@@@@@
string: .........@@@@@@@@
This is a match!
Whereas when checking "longer", we're in this situation:
pattern: @@@@@@@@@
string: .........@@@@@@@@
Algorithm says: ^ these last characters don't match.
^ this next character *is* in the pattern.
We can't jump forward.
pattern: @@@@@@@@
string: .........@@@@@@@@
Start comparing at every single alignment...
I'm attaching reproducer.py, which replicates this from scratch without loading data from a file.
|
|||
| msg378260 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-08 17:31 | |
Good sleuthing, Dennis! Yes, Fredrik was not willing to add "potentially expensive" (in time or in space) tricks: http://effbot.org/zone/stringlib.htm So worst-case time is proportional to the product of the arguments' lengths, and the cases here appear to, essentially, hit that. It _was_ a goal that it always be at least as fast as the dirt-dumb search algorithm it replaced, and in good real-life (not just contrived) cases to be much faster. It met the goals it had. |
|||
| msg378263 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-08 18:01 | |
Just FYI, the original test program did get the right answer for the second search on my box - after about 3 1/2 hours :-) |
|||
| msg378301 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-09 03:53 | |
BTW, this initialization in the FASTSEARCH code appears to me to be a mistake:
skip = mlast - 1;
That's "mistake" in the sense of "not quite what was intended, and so confusing", not in the sense of "leads to a wrong result".
I believe `skip` should be initialized to plain `mlast` instead. Setting it to something smaller than that (like to `mlast - 1`) doesn't cause an error, but fails to exploit as much skipping as possible.
`mlast - 1` is the same value `skip` is set to if the following loop finds that the last character of the pattern is also the pattern's first character, but doesn't appear elsewhere in the pattern. It can be one larger if the last pattern character is unique in the pattern (which is the initial value of `skip` set by the line shown above).
|
|||
| msg378329 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-09 14:56 | |
The attached fastsearch.diff removes the speed hit in the original test case and in the constructed one. I don't know whether it "should be" applied, and really can't make time to dig into it. The rationale: when the last characters of the pattern string and the current search window don't match, this is what happens: if the "Bloom filter" can prove that the character one beyond the search window isn't in the pattern at all, the search window is advanced by len(pattern) + 1 positions. Else it's advanced only 1 position. What changes here: if the Bloom filter thinks the character one beyond the search window may be in the pattern, this goes on to see whether the Bloom filter thinks the last character in the search window may be in the pattern (by case assumption, we already know it's not the _last_ character in the pattern). If not, the search window can be advanced by len(pattern) positions. So it adds an extra check in the last-characters-don't-match and next-character-may-be-in-the-pattern case: if the last character is not in the pattern, it's irrelevant that the next character may be - there's no possible overall match including the last character, so we can move the search window beyond it. The question is whether this costs more than it saves overall. It saves literally hours of CPU time for one search in this report's case ;-) But worst-case time remains O(m*n) regardless, just somewhat harder to provoke. |
|||
| msg378372 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-10 08:25 | |
I agree that skip could could do 1 better.
---
> I don't know whether it "should be" applied
I don't think I'm convinced: the second check fixes only the very specific case when s[len(p):].startswith(p).
Perturbations of reproducer.py are still very slow with the patch:
- pattern2 = b"B" * BIG
+ pattern2 = b"B" * (BIG + 10)
In fact, it's even slower than before due to the double-checking.
---
I'd be curious how something like Crochemore and Perrin's "two-way" algorithm would do (constant space, compares < 2n-m):
http://www-igm.univ-mlv.fr/~lecroq/string/node26.html#SECTION00260
https://en.wikipedia.org/wiki/Two-way_string-matching_algorithm
Apparently it's been used as glibc's memmem() since 2008. There, it additionally computes a table, but only for long needles where it really pays off:
https://code.woboq.org/userspace/glibc/string/str-two-way.h.html
https://code.woboq.org/userspace/glibc/string/memmem.c.html
Although there certainly seems to be a complexity rabbithole here that would be easy to over-do.
I might look more into this.
|
|||
| msg378420 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-11 03:37 | |
Ya, the case for the diff is at best marginal. Note that while it may be theoretically provable that the extra test would make the worst cases slower, that's almost certainly not measurable. The extra test would almost never be executed in the worst cases: in those the last characters of the needle and haystack DO match, and we spend almost all the total time in the
for (j = 0; j < mlast; j++)
loop. The extra test is only in the branch where the last characters _don't_ match.
In that branch, it's already certain that the last haystack character does not match the last needle character, so in a probabilistic sense, for "random" data that increases the odds that the last haystack character isn't in the needle at all. In which case the payoff is relatively large compared to the cost of the test (can skip len(needle) positions at once, instead of only 1).
I don't believe this can be out-thought. It would require timing on "typical" real-life searches. Which are likely impossible to obtain ;-)
Offhand do you know what the _best_ timing for two-way search is in a pattern-not-found case? The algorithm is too complicated for that to be apparent to me at a glance. As Fredrik said in the post of his I linked to, he was very keen to have an algorithm with best case sublinear time. For example, the one we have takes best-case not-found O(n/m) time (where n is the haystack length and m the needle length). For example, searching for 'B' * 1_000_000 in 'A' * 10_000_000 fails after just 9 character comparisons (well, not counting the million less 1 compares to initialize `skip` to the ultimately useless 0).
|
|||
| msg378423 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-11 06:51 | |
> Offhand do you know what the _best_ timing for two-way search is in a pattern-not-found case?
Looking at the glibc implementation, in the top-level "else" clause
(for when the string isn't completely periodic),
we have:
period = MAX (suffix, needle_len - suffix) + 1;
so period > needle_len / 2.
Then during each iteration of the j-loop (where j is the index into the haystack),
j is sometimes incremented by `period`, which would probably give O(n/m) best case.
Here's a sublinear example for the two-way algorithm:
N = 10**7
haystack = "ABC" * N
needle1 = "ABC" * (N // 10) + "DDD"
needle2 = "ABC" * 10 + "DDD"
=== Results ===
Pure Python Two-Way, shorter needle: 1.7142754
Pure Python Two-Way. Longer needle: 0.0018845000000000667
Python builtin, shorter needle: 0.031071400000000082
Python builtin, longer needle: 0.030566099999999707
This case is surprisingly better than the builtin:
N = 10**7
haystack = "ABC" * N
needle1 = "DDD" + "ABC" * (N // 10)
needle2 = "DDD" + "ABC" * 10
=== Results ===
Pure Python Two-Way, shorter needle: 0.0020895000000000774
Pure Python Two-Way. Longer needle: 0.0017878999999999534
Python builtin, shorter needle: 0.029998100000000028
Python builtin, longer needle: 0.02963439999999995
This was measured using the attached fastsearch.py. There are some manipulations in there like string slicing that would make more sense as pointer math in C, so especially accounting for that, I'm guessing it would be pretty competitive in a lot of cases.
A lot of the implementations look like they use a complete Boyer-Moore table to go sublinear in even more cases, which it seems we want to avoid. I'm not certain, but it's conceivable that the existing techniques of using just one one delta-value or the "Bloom filter" could be thrown in there to get some of the same improvements. Although that could be redundant -- I'm not sure.
|
|||
| msg378470 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-12 05:06 | |
Impressive, Dennis! Nice work. FYI, on the OP's original test data, your fastsearch() completes each search in under 20 seconds using CPython, and in well under 1 second using PyPy. Unfortunately, that's so promising it can't just be dismissed offhandedly ;-) Looks like something quite worth pursuing here! |
|||
| msg378472 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-12 07:00 | |
Here is a C implementation of the two-way algorithm that should work as a drop-in replacement for Objects/stringlib/fastsearch.h. Benchmarking so far, it looks like it is a bit slower in a lot of cases. But it's also a bit faster in a some other cases and oodles faster in the really bad cases. I wonder if there's a good heuristic cutoff (for the needle size?) where the two-way usually becomes better. |
|||
| msg378534 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-12 23:50 | |
PR 22679 is a draft that does the two-way algorithm but also adds both of the tricks from Fredrik's implementation: a bit-set "bloom filter" and remembering the skip-distance between some pair of characters. |
|||
| msg378537 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-12 23:55 | |
I used random_bench.py to compare PR 22679 to Master, and the results are in bench_results.txt. Results were varied. I suppose this depends on what cases we want to optimize for. |
|||
| msg378541 - (view) | Author: STINNER Victor (vstinner) * |
Date: 2020-10-13 07:06 | |
> I used random_bench.py to compare PR 22679 to Master, and the results are in bench_results.txt. Results were varied. I suppose this depends on what cases we want to optimize for. Lazy me: can you please use render results as a table? Use something like: ./python random_bench.py -o ref.json # master reference # apply your change, rebuild Python ./python random_bench.py -o change.json # your change python3 -m pyperf compare_to --table ref.json change.json https://pyperf.readthedocs.io/en/latest/cli.html#compare-to-cmd See also -G option. |
|||
| msg378543 - (view) | Author: STINNER Victor (vstinner) * |
Date: 2020-10-13 07:13 | |
random_bench.py has really weird timings. Example: (...) Run 15: 1 warmup, 3 values, 2^15 loops - warmup 1: 3.05 us (+504%) - value 1: 42.8 ns (-92%) - value 2: 1.18 us (+133%) - value 3: 293 ns (-42%) (...) Run 21: 1 warmup, 3 values, 2^15 loops - warmup 1: 167 us (+1073%) - value 1: 162 ns (-99%) - value 2: 39.1 us (+174%) - value 3: 3.53 us (-75%) needle=3: Mean +- std dev: 17.2 us +- 39.6 us How is it possible that in the same process (same "Run"), timing changes between 42 ns and 1 180 ns? The std dev is really large. |
|||
| msg378556 - (view) | Author: STINNER Victor (vstinner) * |
Date: 2020-10-13 11:42 | |
FYI after I saw bench_results.txt, I wrote a pyperf PR to add geometric mean, to more easily summarize a benchmark suite :-D https://github.com/psf/pyperf/pull/79 |
|||
| msg378576 - (view) | Author: STINNER Victor (vstinner) * |
Date: 2020-10-13 21:04 | |
I compared PR 22679 using the commit 77f0a23e7a9fb247101b9b14a060c4ba1c4b87a5 as the reference using random_bench.py. For a bunch of cases it's slower, for some others it's faster. My modified pyperf computes a geometric mean of: 0.70 (faster). $ PYTHONPATH=~/myprojects/pyperf/ python3 -m pyperf compare_to ref.json pr22679.json -G Slower (4): - needle=8: 816 us +- 227 us -> 1.13 ms +- 0.60 ms: 1.38x slower (+38%) - needle=16: 579 us +- 208 us -> 780 us +- 391 us: 1.35x slower (+35%) - needle=7: 865 us +- 301 us -> 1.15 ms +- 0.70 ms: 1.33x slower (+33%) - needle=9: 827 us +- 250 us -> 1.04 ms +- 0.53 ms: 1.26x slower (+26%) Faster (18): - needle=3442: 2.24 ms +- 1.17 ms -> 846 us +- 895 us: 2.65x faster (-62%) - needle=301: 1.72 ms +- 1.13 ms -> 652 us +- 774 us: 2.64x faster (-62%) - needle=5164: 2.51 ms +- 1.24 ms -> 991 us +- 972 us: 2.53x faster (-60%) - needle=1529: 2.43 ms +- 1.14 ms -> 967 us +- 841 us: 2.51x faster (-60%) - needle=2: 660 ns +- 1060 ns -> 263 ns +- 627 ns: 2.50x faster (-60%) - needle=11621: 2.40 ms +- 1.02 ms -> 960 us +- 931 us: 2.50x faster (-60%) - needle=679: 2.48 ms +- 1.11 ms -> 1.03 ms +- 0.95 ms: 2.42x faster (-59%) - needle=1019: 2.48 ms +- 1.28 ms -> 1.08 ms +- 0.99 ms: 2.30x faster (-56%) - needle=2294: 2.47 ms +- 1.17 ms -> 1.07 ms +- 0.93 ms: 2.30x faster (-56%) - needle=452: 2.14 ms +- 0.99 ms -> 963 us +- 956 us: 2.23x faster (-55%) - needle=17432: 2.24 ms +- 1.00 ms -> 1.12 ms +- 0.90 ms: 2.00x faster (-50%) - needle=7747: 2.24 ms +- 1.18 ms -> 1.14 ms +- 0.99 ms: 1.97x faster (-49%) - needle=26149: 2.29 ms +- 0.85 ms -> 1.33 ms +- 0.98 ms: 1.72x faster (-42%) - needle=58837: 2.24 ms +- 1.00 ms -> 1.35 ms +- 0.94 ms: 1.66x faster (-40%) - needle=88256: 2.40 ms +- 0.97 ms -> 1.52 ms +- 0.88 ms: 1.58x faster (-37%) - needle=39224: 2.20 ms +- 1.00 ms -> 1.50 ms +- 0.92 ms: 1.46x faster (-32%) - needle=88: 584 us +- 271 us -> 462 us +- 324 us: 1.26x faster (-21%) - needle=1: 24.7 ns +- 2.4 ns -> 23.8 ns +- 2.1 ns: 1.04x faster (-4%) Benchmark hidden because not significant (10): needle=3, needle=4, needle=5, needle=6, needle=10, needle=25, needle=38, needle=58, needle=133, needle=200 Geometric mean: 0.70 (faster) 22:12:11 vstinner@apu$ PYTHONPATH=~/myprojects/pyperf/ python3 -m pyperf compare_to ref.json pr22679.json --table -G +----------------+---------+------------------------------+ | Benchmark | ref | pr22679 | +================+=========+==============================+ | needle=8 | 816 us | 1.13 ms: 1.38x slower (+38%) | +----------------+---------+------------------------------+ | needle=16 | 579 us | 780 us: 1.35x slower (+35%) | +----------------+---------+------------------------------+ | needle=7 | 865 us | 1.15 ms: 1.33x slower (+33%) | +----------------+---------+------------------------------+ | needle=9 | 827 us | 1.04 ms: 1.26x slower (+26%) | +----------------+---------+------------------------------+ | needle=1 | 24.7 ns | 23.8 ns: 1.04x faster (-4%) | +----------------+---------+------------------------------+ | needle=88 | 584 us | 462 us: 1.26x faster (-21%) | +----------------+---------+------------------------------+ | needle=39224 | 2.20 ms | 1.50 ms: 1.46x faster (-32%) | +----------------+---------+------------------------------+ | needle=88256 | 2.40 ms | 1.52 ms: 1.58x faster (-37%) | +----------------+---------+------------------------------+ | needle=58837 | 2.24 ms | 1.35 ms: 1.66x faster (-40%) | +----------------+---------+------------------------------+ | needle=26149 | 2.29 ms | 1.33 ms: 1.72x faster (-42%) | +----------------+---------+------------------------------+ | needle=7747 | 2.24 ms | 1.14 ms: 1.97x faster (-49%) | +----------------+---------+------------------------------+ | needle=17432 | 2.24 ms | 1.12 ms: 2.00x faster (-50%) | +----------------+---------+------------------------------+ | needle=452 | 2.14 ms | 963 us: 2.23x faster (-55%) | +----------------+---------+------------------------------+ | needle=2294 | 2.47 ms | 1.07 ms: 2.30x faster (-56%) | +----------------+---------+------------------------------+ | needle=1019 | 2.48 ms | 1.08 ms: 2.30x faster (-56%) | +----------------+---------+------------------------------+ | needle=679 | 2.48 ms | 1.03 ms: 2.42x faster (-59%) | +----------------+---------+------------------------------+ | needle=11621 | 2.40 ms | 960 us: 2.50x faster (-60%) | +----------------+---------+------------------------------+ | needle=2 | 660 ns | 263 ns: 2.50x faster (-60%) | +----------------+---------+------------------------------+ | needle=1529 | 2.43 ms | 967 us: 2.51x faster (-60%) | +----------------+---------+------------------------------+ | needle=5164 | 2.51 ms | 991 us: 2.53x faster (-60%) | +----------------+---------+------------------------------+ | needle=301 | 1.72 ms | 652 us: 2.64x faster (-62%) | +----------------+---------+------------------------------+ | needle=3442 | 2.24 ms | 846 us: 2.65x faster (-62%) | +----------------+---------+------------------------------+ | Geometric mean | (ref) | 0.70 (faster) | +----------------+---------+------------------------------+ Not significant (10): needle=5; needle=4; needle=38; needle=10; needle=6; needle=200; needle=58; needle=25; needle=3; needle=133 |
|||
| msg378578 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-13 21:30 | |
> For a bunch of cases it's slower, for some others it's faster.
I have scant real idea what you're doing, but in the output you showed 4 output lines are labelled "slower" but 18 are labelled "faster".
What you wrote just above appears to say the reverse (I'd call 18 "a bunch" compared to 4 "some others").
Could please state plainly which of {status quo, PR} is faster on an output line labelled "faster"?
My a priori guess was that the PR had the highest chance of being slower when the needle is short and is found in the haystack early on. Then preprocessing time accounts for a relatively higher percentage of the total time taken, and the PR's preprocessing is more expensive than the status quo's.
The alphabet size here is small (just 26 possible letters, from `ascii_uppercase`), so it's quite likely that a short needle _will_ be found early on in a long haystack.
|
|||
| msg378579 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-13 21:42 | |
bench_table.txt gives my results (`ref` is Master, `change` is with PR 22679). The change gives 342 faster cases and 275 slower cases, and 9 cases with no change. I chose a random word of length 10**6 with a zipf character distribution for the haystack, then 20 random needles (also zipf) of each length and tested those same needles and haystack for both. I ran then with this: from lots_of_benches import needles, haystack needles: list[str] haystack: str from pyperf import Runner runner = Runner() for needle in needles: n = len(needle) abbrev = needle if n <= 10 else f"{needle[:10]}..." runner.timeit( name=f"length={n}, value={abbrev}", stmt=f"needle in haystack", globals=globals(), ) |
|||
| msg378582 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-13 22:03 | |
Dennis, would it be possible to isolate some of the cases with more extreme results and run them repeatedly under the same timing framework, as a test of how trustworthy the _framework_ is? From decades of bitter experience, most benchmarking efforts end up chasing ghosts ;-) For example, this result: length=3442, value=ASXABCDHAB... | 289 us | 2.36 ms: 8.19x slower (+719%) Is that real, or an illusion? Since the alphabet has only 26 letters, it's all but certain that a needle that long has more than one instance of every letter. So the status quo's "Bloom filter" will have every relevant bit set, rendering its _most_ effective speedup trick useless. That makes it hard (but not impossible) to imagine how it ends up being so much faster than a method with more powerful analysis to exploit. |
|||
| msg378583 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-13 22:47 | |
Another algorithmic possibility: Instead of the bitset, we could have a stack-allocated
uint8_t jump[32]; // maybe 64? Maybe uint16_t?
It would say this: If the last character lined up in the haystack is congruent to i mod (1 << 8), then jump ahead by (neede_len if jump[i]==255 else jump[i]), where jump[i] gives the distance between the end of the needle and the last occurrence in the needle of a character congruent to i.
Is this sort of constant-but-more-than-a-few-bytes stack-space an acceptable constant memory cost? If so, I believe that could be a big improvement.
There are also a bunch of little tweaks that could be done here: For example, should a hypothetical jump-table jump to line up the last character in the needle, or jump to line up the middle character in the needle? The max from two tables? Should we search for the last characters to be equal, or just make sure the last character is in the needle-bit-set (like in the PR)? Should there be a second bit-set for the right half of the string? Should there be a skip value computed for the last character as well as the middle character (middle character only in the PR)? etc. etc. I'll be sure to try some of these things.
|
|||
| msg378584 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-13 22:51 | |
@Tim I got this again for that benchmark: length=3442, value=ASXABCDHAB...: Mean +- std dev: 2.39 ms +- 0.01 ms Unfortunately not a ghost. |
|||
| msg378585 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-13 22:56 | |
That test needle happened to end with a G and not have another G until much earlier. The status quo took advantage of that, but the PR only takes advantage of the skip value for a certain middle character. Perhaps it could do both. |
|||
| msg378590 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-14 01:06 | |
Dennis, I'm delighted that the timing harness pointed out an actual glitch, and that it was so (seemingly) straightforward to identify the algorithmic cause. This gives me increased confidence that this project can be pushed to adoption, and your name will be hallowed in Python's history :-) I have no problem with increasing the constant space. Fredrik was Python's Unicode pioneer too, so was naturally repelled by any scheme that required additional space proportional to the alphabet size. The "Bloom filter" is the tiny bit left of Daniel Sunday's algorithm, which actually has no such thing ;-) Along the lines you suggested, Sunday precomputes a vector indexed by characters, each entry giving the distance to that character's rightmost index in the needle. The "Bloom filter" throws that vector away and only saves hashes of the indices where the vector holds its maximum possible value. Note that there's nothing magical about "right to left" in Sunday's algorithm (or, really, in our current use of the Bloom filter). Characters can be compared in any order, and when there's a mismatch, the skip vector can be indexed by the character one beyond the search window to often find a decent amount to skip. Indeed, in apps where the expected frequency of characters is known, Sunday's algorithm is often adapted to compare the least-frequently expected needle character first. The downside isn't really the space, but that stack space is uninitialized trash. Initializing it to a known value increases preprocessing overhead, albeit independent of needle length. So the relative overhead is higher the shorter the needle. I agree expanding it beyond the tiny bit vector is likely to be significantly helpful. There's no discomfort at all to me if, e.g., it stored 32-bit counts and is indexed by the last 6 bits of the character. That's a measly 256 bytes in all. It's also possible that a more capable "Sunday-ish vector" of this kind would render the current `skip` trick usually useless by comparison. Or not ;-) |
|||
| msg378600 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-14 03:03 | |
> There's no discomfort at all to me if, e.g., it stored > 32-bit counts and is indexed by the last 6 bits of the > character. That's a measly 256 bytes in all. Or, for the same space, 16-bit counts indexed by the last 7 bits. Then there's no aliasing for 7-bit ASCII, which is still very common in my world ;-) Needles over 64K characters aren't. Which is a weird rule of thumb that's served me well, although for no solid reason I can detect: when faced with a universe of tradeoff possibilities for which it appears impossible to get a handle on "the typical" case, optimize for _your_ cases. Then at least one user will be delighted in the end :-) |
|||
| msg378635 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-14 16:20 | |
For completeness, a link to the python-dev thread about this: https://mail.python.org/archives/list/python-dev@python.org/thread/ECAZN35JCEE67ZVYHALRXDP4FILGR53Y/#4IEDAS5QAHF53IV5G3MRWPQAYBIOCWJ5 |
|||
| msg378652 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-14 21:14 | |
The most recent batch of commits added a jump table. Between master and PR 22679 now, there are 151 cases slower than master and 463 that faster than master. The slower cases are at most twice as slow, but the faster cases are often 10-20x faster. I could add a cutoff to use a simpler algorithm instead, for needles of length less than ~10, but I wanted to get the "purer" data out before making that change. The benchmark data is here: https://pastebin.com/raw/bzQ4xQgM |
|||
| msg378736 - (view) | Author: Gregory P. Smith (gregory.p.smith) * |
Date: 2020-10-16 19:14 | |
FWIW I think your numbers look good, a small needle cut-off is likely a good idea. |
|||
| msg378737 - (view) | Author: Gregory P. Smith (gregory.p.smith) * |
Date: 2020-10-16 19:17 | |
Another potential algorithm to consider in large needle situations is a Rabin-Karp rolling hash string search. If used, it's the kind of algorithm that I'd probably bail out to an alternate method on if a run of Rabin-Karp started having a high percentage of false positive failed comparisons (suggesting data antagonistic to the chosen rolling hash algorithm(s) which would degenerate performance back to Needle*Haystack territory). |
|||
| msg378739 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-16 19:39 | |
I'm doing a couple more timing tests to try to understand exactly when the cutoff should be applied (based on some combination of needle and haystack lengths). Can the rolling hash algorithm be made to go sublinear like O(n/m)? It looked like it was pretty essential that it hash/unhash each and every haystack character. You could probably do a bloom-like check where you jump ahead by the needle length sometimes, but you'd then have to re-hash the m characters in the new window anyway. |
|||
| msg378742 - (view) | Author: Gregory P. Smith (gregory.p.smith) * |
Date: 2020-10-16 19:52 | |
I assume a rolling hash is linear at best, even if you do add some skip ahead checks. |
|||
| msg378750 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-16 21:08 | |
I don't think Rabin-Karp is worth trying here. The PR is provably worst-case linear time, and the constant factor is already reasonably small. Its only real weakness I can see is that it can be significantly (but seemingly not dramatically) slower than the status quo, in what are exceptionally good cases for the status quo, and perhaps most often due to the increased preprocessing cost of the new code (which is relatively most damaging if the needle is found early in the haystack - in which cases preprocessing can be close to a pure waste of time). The status quo and the PR both enjoy sublinear (O(len(haystack) / len(needle)) cases too, but R-K doesn't. Where R-K is a "go to" choice is when an app needs to search the same large text for several strings (Wikipedia has a decent description of R-K can be adapted to that) - but Python has no string API that does such a thing (closest is joining the search-for strings via "|" for a regexp search). |
|||
| msg378751 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-16 21:11 | |
Removed 3.8 from the Versions list. The code was functioning as designed, and the O(n*m) worst case bounds were always known to be possible, so there's no actual bug here. |
|||
| msg378753 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-16 21:13 | |
And changed the "Type" field to "performance", because speed is the only issue here. |
|||
| msg378793 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-16 23:50 | |
BTW, in the old post of Fredrick's I linked to, he referred to a "stringbench.py" program he used for timings, but the link is dead. I was surprised to find that it still lives on, under the Tools directory. Or did - I'm on Windows now and its Python distro doesn't always have everything in a Linux distro, for "reasons" I can't remember ;-) Anyway, here on GitHub: https://github.com/python/cpython/tree/master/Tools/stringbench |
|||
| msg378828 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-17 20:25 | |
I added the cutoff for strings >= 10 characters, and I converted the PR from a draft to "Ready to Review."
When running stringbench.py before and after the PR, I get these results:
Summary:
Unicode Before: 81.82 Bytes Before: 92.62
Unicode After: 64.70 Bytes after: 62.41
Full results here:
https://pastebin.com/raw/DChzMjhH
And on the random zipf benchmarks:
Summary:
14 cases slower (median 1.16x slower, at most 1.52x slower)
601 cases faster (median 2.15x faster, at most 21.94x faster)
Full results here:
https://pastebin.com/raw/ez6529Bp
|
|||
| msg378834 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-17 20:51 | |
When I ran stringbench yesterday (or the day before - don't remember), almost all the benefit seemed to come from the "late match, 100 characters" tests. Seems similar for your run. Here are your results for just that batch, interleaving the two runs to make it easy to see: first line from the "before" run, second line from the "after" (PR) run, then a blank line. Lather, rinse, repeat.
These are dramatic speedups for the "search forward" cases. But there _also_ seem to be real (but much smaller) benefits for the "search backward" cases, which I don't recall seeing when I tried it. Do you have a guess as to why?
========== late match, 100 characters
bytes unicode
(in ms) (in ms) ratio%=bytes/unicode*100
2.73 3.88 70.4 s="ABC"*33; ((s+"D")*500+s+"E").find(s+"E") (*100)
0.17 0.15 116.3 s="ABC"*33; ((s+"D")*500+s+"E").find(s+"E") (*100)
2.01 3.54 56.8 s="ABC"*33; ((s+"D")*500+"E"+s).find("E"+s) (*100)
0.89 0.87 101.8 s="ABC"*33; ((s+"D")*500+"E"+s).find("E"+s) (*100)
1.66 2.36 70.2 s="ABC"*33; (s+"E") in ((s+"D")*300+s+"E") (*100)
0.15 0.13 111.5 s="ABC"*33; (s+"E") in ((s+"D")*300+s+"E") (*100)
2.74 3.89 70.5 s="ABC"*33; ((s+"D")*500+s+"E").index(s+"E") (*100)
0.17 0.15 112.4 s="ABC"*33; ((s+"D")*500+s+"E").index(s+"E") (*100)
3.93 4.00 98.4 s="ABC"*33; ((s+"D")*500+s+"E").partition(s+"E") (*100)
0.30 0.27 108.0 s="ABC"*33; ((s+"D")*500+s+"E").partition(s+"E") (*100)
3.99 4.59 86.8 s="ABC"*33; ("E"+s+("D"+s)*500).rfind("E"+s) (*100)
3.13 2.51 124.5 s="ABC"*33; ("E"+s+("D"+s)*500).rfind("E"+s) (*100)
1.64 2.23 73.3 s="ABC"*33; (s+"E"+("D"+s)*500).rfind(s+"E") (*100)
1.54 1.82 84.5 s="ABC"*33; (s+"E"+("D"+s)*500).rfind(s+"E") (*100)
3.97 4.59 86.4 s="ABC"*33; ("E"+s+("D"+s)*500).rindex("E"+s) (*100)
3.18 2.53 125.8 s="ABC"*33; ("E"+s+("D"+s)*500).rindex("E"+s) (*100)
4.69 4.67 100.3 s="ABC"*33; ("E"+s+("D"+s)*500).rpartition("E"+s) (*100)
3.37 2.66 126.9 s="ABC"*33; ("E"+s+("D"+s)*500).rpartition("E"+s) (*100)
4.09 2.82 145.0 s="ABC"*33; ("E"+s+("D"+s)*500).rsplit("E"+s, 1) (*100)
3.39 2.62 129.5 s="ABC"*33; ("E"+s+("D"+s)*500).rsplit("E"+s, 1) (*100)
3.50 3.51 99.7 s="ABC"*33; ((s+"D")*500+s+"E").split(s+"E", 1) (*100)
0.30 0.28 106.0 s="ABC"*33; ((s+"D")*500+s+"E").split(s+"E", 1) (*100)
Just for contrast, doesn't make much difference for the "late match, two characters" tests:
========== late match, two characters
0.44 0.58 76.2 ("AB"*300+"C").find("BC") (*1000)
0.57 0.48 120.2 ("AB"*300+"C").find("BC") (*1000)
0.59 0.73 80.5 ("AB"*300+"CA").find("CA") (*1000)
0.56 0.72 77.5 ("AB"*300+"CA").find("CA") (*1000)
0.55 0.49 112.5 "BC" in ("AB"*300+"C") (*1000)
0.66 0.37 177.7 "BC" in ("AB"*300+"C") (*1000)
0.45 0.58 76.5 ("AB"*300+"C").index("BC") (*1000)
0.57 0.49 116.5 ("AB"*300+"C").index("BC") (*1000)
0.61 0.62 98.6 ("AB"*300+"C").partition("BC") (*1000)
0.72 0.52 137.2 ("AB"*300+"C").partition("BC") (*1000)
0.62 0.64 96.4 ("C"+"AB"*300).rfind("CA") (*1000)
0.49 0.49 101.6 ("C"+"AB"*300).rfind("CA") (*1000)
0.57 0.65 87.5 ("BC"+"AB"*300).rfind("BC") (*1000)
0.51 0.57 89.3 ("BC"+"AB"*300).rfind("BC") (*1000)
0.62 0.64 96.5 ("C"+"AB"*300).rindex("CA") (*1000)
0.50 0.49 101.2 ("C"+"AB"*300).rindex("CA") (*1000)
0.68 0.69 99.0 ("C"+"AB"*300).rpartition("CA") (*1000)
0.61 0.54 113.5 ("C"+"AB"*300).rpartition("CA") (*1000)
0.82 0.60 137.8 ("C"+"AB"*300).rsplit("CA", 1) (*1000)
0.63 0.57 112.0 ("C"+"AB"*300).rsplit("CA", 1) (*1000)
0.63 0.61 103.0 ("AB"*300+"C").split("BC", 1) (*1000)
0.74 0.54 138.2 ("AB"*300+"C").split("BC", 1) (*1000)
|
|||
| msg378836 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-17 21:35 | |
> But there _also_ seem to be real (but much smaller) benefits > for the "search backward" cases, which I don't recall seeing > when I tried it. Do you have a guess as to why? I did change `skip = mlast - 1;` to `skip = mlast;` as you had pointed out. So it could be that, or just a compiler/benchmark ghost. |
|||
| msg378842 - (view) | Author: Guido van Rossum (gvanrossum) * |
Date: 2020-10-18 00:12 | |
This may be irrelevant at this point, but trying to understand the original reproducer, I wanted to add my 1c worth. It seems Dennis' reproducer.py is roughly this: (I'm renaming BIG//3 to K to simplify the math.) aaaaaBBBBBaaaaaBBBBBBBBBBBBBBB (haystack, length K*6) BBBBBBBBBBBBBBB (needle, length K*3) The needle matches exactly once, at the end. (Dennis uses BIG==10**6, which leaves a remainder of 1 after dividing by 3, but that turns out to be irrelevant -- it works with BIG==999999 as well.) The reproducer falls prey to the fact that it shifts the needle by 1 each time (for the reason Tim already explained). At each position probed, the sequence of comparisons is (regardless of the bloom filter or skip size, and stopping at the first mismatch): - last byte of needle - first, second, third, etc. byte of needle As long as the needle's first character corresponds to an 'a' (i.e., K times) this is just two comparisons until failure, but once it hits the first run of 'B's it does K+1 comparisons, then shifts by 1, does another K+1 comparisons, and so on, for a total of K times. That's K**2 + K, the source of the slowdown. Then come K more quick misses, followed by the final success. (Do we know how the OP found this reproducer? The specific length of their needle seems irrelevant, and I don't dare look in their data file.) Anyway, thinking about this, for the current (unpatched) code, here's a somewhat simpler reproducer along the same lines: BBBBBaaaaaBBBBB (haystack, length K*3) BBBBBBBBBB (needle, length K*2) This immediately starts doing K sets of K+1 comparisons, i.e. K**2 + K again, followed by failure. I am confident this has no relevance to the Two-Way algorithm. |
|||
| msg378843 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-18 01:04 | |
I don't think we have any idea how the OP stumbled into this. Looks like it "just happened". The case you construted is quadratic-time, but not quite as bad: BBBBBaaaaaBBBBB BBBBBBBBBB Fails at once, because 'a' doesn't match the trailing needle 'B'. The Bloom filter is useless because the next haystack 'B' _is_ in the needle. So shift right 1: BBBBBaaaaaBBBBB xBBBBBBBBBB Last character matches, so goes on to compare 4 Bs and an aB mismatch. 6 in all. Bloom filter useless again, and another shift by 1: BBBBBaaaaaBBBBB xxBBBBBBBBBB Now there's 1 less compare, because only 3 Bs match. And so on. After the next shift, only 2 Bs match, and after the shift following that, only 1 B. Getting to: BBBBBaaaaaBBBBB xxxxxBBBBBBBBBB Now after matching the trailing Bs, aB mismatches at once. And we're done, because another shift by 1 moves the end of the needle beyond the end of the haystack (although I bet the Bloom filter reads up the trailing NUL byte from the haystack and actually makes a "giant" shift). You're right that two-way yawns at this ;-) 'B' * (K*2) is split into u = "" # empty string! v = 'B' * (K*2) so only the "match the right half" part of the searching algorithm comes into play. BBBBBaaaaaBBBBB BBBBBBBBBB first mismatches at the 6th character (1-based counting - at index 5), so it shifts right by 6: BBBBBaaaaaBBBBB xxxxxxBBBBBBBBBB And it's done, because the needle has moved beyond the end of the haystack. The brainpower that went into making this "look trivial" is quite impressive :-) |
|||
| msg378844 - (view) | Author: Guido van Rossum (gvanrossum) * |
Date: 2020-10-18 01:45 | |
Right, so IIUC the *quadratic* portion of Dennis’ original reproducer, aBaBBB with pattern BBB, except with more cowbell :-) acts the same. |
|||
| msg378847 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-18 02:09 | |
Yup, they act essentially the same, but yours jumps into the quicksand earlier ;-) I'm fond of this one: """ HUGE = 10**7 BIG = 10**6 bigxs = 'x' * BIG haystack = 'x' * HUGE needle = bigxs + 'y' + bigxs """ "The problem" then is in middle of the needle, not at either end, so really simple tricks all fail. For example, set(haystack) is a subset of set(needle), so our "Bloom filter" is useless, and needle[-1] == needle[-2], so our "skip" count is the useless 0. Pure brute force is quadratic-time, and we're even slower because we're paying over & over to try heuristic speedups that happen never to pay off. Two-way splits the needle as u = bigxs v = 'y' + bigxs and again never gets out of the "try to match the right part" phase. Each time around it fails to match 'y' on the first try, and shifts right by 1. Boring, but linear time overall. |
|||
| msg378916 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-19 01:24 | |
Below is one of the tests that got run when I happened to import something, and I thought it was a good illustration of the Boyer-Moore bad character shift table. It's worth noting in particular that the table is the dominant force for speed in some common cases, with the two-way stuff only ever being checked once in this example. The shift table can be defeated with pathological strings, and that's where the two-way stuff begins to shine. Checking " 32 bit (ARM)" in "3.10.0a1+ (heads/two-way-dirty:cf4e398e94, Oct 18 2020, 20:09:21) [MSC v.1927 32 bit (Intel)]". ======================== Two-way with needle=" 32 bit (ARM)" and haystack="(heads/two-way-dirty:cf4e398e94, Oct 18 2020, 20:09:21) [MSC v.1927 32 bit (Intel)]" Split " 32 bit (ARM)" into " 32 bit" and " (ARM)". needle is NOT completely periodic. Using period 8. > "(heads/two-way-dirty:cf4e398e94, Oct 18 2020, 20:09:21) [MSC v.1927 32 bit (Intel)]" > " 32 bit (ARM)" Last character not found in string. > "(heads/two-way-dirty:cf4e398e94, Oct 18 2020, 20:09:21) [MSC v.1927 32 bit (Intel)]" > " 32 bit (ARM)" Table says shift by 11. > "(heads/two-way-dirty:cf4e398e94, Oct 18 2020, 20:09:21) [MSC v.1927 32 bit (Intel)]" > " 32 bit (ARM)" # Made the '3's line up Table says shift by 5. > "(heads/two-way-dirty:cf4e398e94, Oct 18 2020, 20:09:21) [MSC v.1927 32 bit (Intel)]" > " 32 bit (ARM)" # Here made the spaces line up Last character not found in string. > "(heads/two-way-dirty:cf4e398e94, Oct 18 2020, 20:09:21) [MSC v.1927 32 bit (Intel)]" > " 32 bit (ARM)" # Made the spaces line up Checking the right half. No match. Jump forward without checking left half. > "(heads/two-way-dirty:cf4e398e94, Oct 18 2020, 20:09:21) [MSC v.1927 32 bit (Intel)]" > " 32 bit (ARM)" # Made the spaces line up Table says shift by 5. > "(heads/two-way-dirty:cf4e398e94, Oct 18 2020, 20:09:21) [MSC v.1927 32 bit (Intel)]" > " 32 bit (ARM)" # Made the spaces line up Table says shift by 5. > "(heads/two-way-dirty:cf4e398e94, Oct 18 2020, 20:09:21) [MSC v.1927 32 bit (Intel)]" > " 32 bit (ARM)" # Made the spaces line up Table says shift by 10. > "(heads/two-way-dirty:cf4e398e94, Oct 18 2020, 20:09:21) [MSC v.1927 32 bit (Intel)]" > " 32 bit (ARM)" # Made the spaces line up Table says shift by 4. > "(heads/two-way-dirty:cf4e398e94, Oct 18 2020, 20:09:21) [MSC v.1927 32 bit (Intel)]" > " 32 bit (ARM)" # Made the lparens line up Last character not found in string. Reached end. Returning -1. |
|||
| msg378917 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-19 01:30 | |
FWIW, one of the "# Made the spaces line up" is actually a "skip ahead by the needle length". |
|||
| msg378920 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-19 03:43 | |
Dennis, I think that's expected, right? Two-way on its own can exploit nothing about individual characters - it only preprocesses the needle to break the possibility for quadratic-time behavior due to periods in the needle. It sounds like you switched the current code's Sunday-ish approach to a more Boyer-Moore-ish approach. That probably hurt, and especially for shorter needles (where Sunday can yield a maximum shift of len(needle)+1, not len(needle) - the "+1" is more significant the smaller len(needle)). Sunday gave 3 variants of his basic algorithm, and in his tests they were all faster than Boyer-Moore, and more so the shorter the needle. Just FYI, here's a scanned PDF of his paper: https://csclub.uwaterloo.ca/~pbarfuss/p132-sunday.pdf |
|||
| msg378922 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-19 04:55 | |
> Dennis, I think that's expected, right? Two-way on its own can exploit nothing about individual characters - it only preprocesses the needle to break the possibility for quadratic-time behavior due to periods in the needle. Yes, that's correct. > It sounds like you switched the current code's Sunday-ish approach to a more Boyer-Moore-ish approach. That probably hurt, and especially for shorter needles (where Sunday can yield a maximum shift of len(needle)+1, not len(needle) - the "+1" is more significant the smaller len(needle)). I'm definitely open to switching things up, but I'm not totally sure there would be a difference. In Sunday, the pattern is somehow scanned at each step, and then upon finding a mismatch, we look up in the table the first character outside the window. With the PR as written, when looking up in the table the last character of the window, we haven't actually produced a mismatch yet; the 'continue' statements jump ahead *until* the last characters match (mod 128), and then the two-way scanning begins, which determines how the window gets shifted after that. But after this two-way-determined shift, the last character in the new window immediately gets looked up again in the table at the top of the loop, effectively letting the two-way shift immediately be extended to a longer shift. I suppose that the line `j += i - suffix + 1;` (which is very often an increment by 1) could be changed to a table lookup of the character just beyond the window, but I don't quite understand why that would be better than incrementing j and then doing the table lookups at the top of the loop. |
|||
| msg378923 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-19 05:16 | |
I posted the example thinking that having a concrete walkthrough might be good for discussion, and it looks like it was. ;-) This makes me curious how a simplified-but-not-as-simplified-as-the-status-quo Sunday algorithm would fare: using the Sunday algorithm, but with a shift lookup modulo 128 rather than a boolean lookup. It might not be provably O(n), but it might be faster for some cases. Although if the common case is already fast enough, maybe we do want a provably-linear algorithm for the big stuff. |
|||
| msg378924 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-19 05:33 | |
I confess I _assumed_ all along that you were generalizing the current code's Sunday trick to 7-bit equivalence classes (up from 32 bits total) and 64K possible shift counts (up from just 2 total possibilities: 1 or len(needle)+1). The Sunday trick couldn't care less where or when the mismatch occurs, just that a mismatch occurred somewhere. In my head I was picturing the paper's code, not the PR. Whenever it makes a shift, it could compare it to the "Sunday-ish shift", and pick the larger. That should have no effect on worst case O() behavior - it would always shift at least as much as Crochempre-Perrin when a mismatch was hit. I can't say how it would relate to details of the PR's spelling, because I'm still trying to fully understand the paper ;-) I don't believe I can usefully review the code before then. |
|||
| msg378979 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-19 18:28 | |
Unfortunately due to licensing issues, it looks like I'll have to ditch the PR and start from scratch: it was too heavily based on the glibc implementation, which has a stricter license. It may be take a good deal of time before I have a potential replacement, but I'll try to work on a "clean-room" implementation. Lesson learned! |
|||
| msg379388 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-23 00:30 | |
I attached a new PR, with a lot of the same ideas. The major differences between this and the last PR: * The first character to be checked at each alignment is the first character of the right half, rather than the last. * If that first character does not match, then the character immediately following the window is looked up in the table, and we jump forward accordingly (Sunday's trick). I'll post some more benchmarks soon, but preliminarily, it seems like this swapping of the character to first be matched is better for some needles, worse for others, which makes sense. Stringbench.py for example has some needles that have a unique character at the end, which prefers the status quo and old PR, but other strings work better for this PR. |
|||
| msg379391 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-10-23 01:10 | |
Note that Sunday doesn't care (at all) where mismatches occur. The "natural" way to add Sunday: follow pure C-P unless/until it finds a mismatching position. Pure C-P then computes a specific shift. Nothing about that changes. But something is added: also compute the shift Sunday suggests, and pick the larger of that and what C-P computed. C-P and Sunday both have cases where they can justify "supernaturally large" shifts (i.e., as long as len(needle), or even that +1 for Sunday), and they're not always the same cases. |
|||
| msg379422 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-23 09:32 | |
This is the approach in the PR:
# JUMP_BOTH
while ...:
if haystack[j + cut] != needle[cut]:
# Sunday skip
j += table[haystack[j + len(needle)]]
continue
j += rest_of_the_two_way_algorithm()
If I understand correctly, this is what you're suggesting:
# JUMP_MAX
while ...:
shift = rest_of_the_two_way_algorithm()
j += max(shift, table[haystack[j + len(needle)]])
I implemented this and on my Zipf benchmark, and JUMP_BOTH was faster on 410 cases (at most 1.86x faster), while JUMP_MAX was faster on 179 cases (at most 1.3x faster).
Some things to notice about the JUMP_BOTH approach:
* The if-statement is actually the first step of the rest_of_the_two_way_algorithm, so there's no extra comparison over the pure two-way algorithm.
* The if-block only executes in situations where the two-way algorithm would say to skip ahead by only 1. In all other situations, the two-way algorithm skips by at least 2.
The typical purpose of the Sunday skip (as far as I can tell) is that in Sunday's algorithm, we find a mismatch, then have no a priori idea of how far ahead to skip, other than knowing that it has to be at least 1, so we check the character 1 to the right of the window. Another way of thinking about this would be to increment the window by 1, look at the last character in the new window, and jump ahead to line it up.
However, with the hybrid method of the PR, we *do* have some a priori skip, bigger than 1, known before we check the table. So instead of doing the maximum of the two-way skip and the Sunday skip, why not do both? As in: do the two-way shift, then extend that with a Sunday shift in the next iteration.
I tried another version also with this in mind, something like:
# JUMP_AFTER
while ...:
# Guaranteed to jump to a mismatched poisition
j += rest_of_the_two_way_algorithm() - 1
j += table[haystack[j + len(needle)]]
But this resulted in slightly-worse performance: JUMP_BOTH was faster in 344 cases (at most 1.9x faster), while JUMP_AFTER was faster in 265 cases (at most 1.32x faster). My guess for the explanation of this is that since most of the time is spent on Sunday shifts lining up the cut character, it's beneficial for the compiler to generate specialized code for that case.
|
|||
| msg379494 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-10-23 23:14 | |
Here are those zipf-distributed benchmarks for PR 22904: https://pastebin.com/raw/qBaMi2dm Ignoring differences of <5%, there are 33 cases that get slower, but 477 cases that got faster. Here's a stringbench.py run for PR 22904: https://pastebin.com/raw/ABm32bA0 It looks like the stringbench times get a bit worse on a few cases, but I would attribute that to the benchmarks having many "difficult" cases with a unique character at the end of the needle, such as: s="ABC"*33; ((s+"D")*500+s+"E").find(s+"E"), which the status quo already handles as well as possible, whereas the PR best handles the case where some middle "cut" character is unique. Who knows how common these cases are. |
|||
| msg379822 - (view) | Author: Tal Einat (taleinat) * |
Date: 2020-10-28 08:15 | |
After spending quite a while setting up my dev machine for (hopefully) reliable benchmarking, I can say with a high level of certainty that the latest PR (GH-22904, commit fe9e9d9c1f1c5f98c797d19e2214d1413701f6de) runs stringbench.py significantly faster than the master branch (commit fb5db7ec58624cab0797b4050735be865d380823). See attached results. I've also run the zipf-distributed random string benchmarks provided by Dennis, with a slight addition of `random.seed(1)` in the do_timings function. Those show significant, consistent improvements on needles of length over 100, but not on shorter needles. The results are also found in the attached file. My conclusion is that the current two-way implementation is certainly better for needles of length over 100, but for shorter needles the situation is still unclear. System details: Dell XPS 9560 Intel i7-7700HQ Ubuntu 20.04 Steps taken to prepare system for performance tuning: * Enable CPU isolation for two physical cores * Disable Intel p-state driver * Disable turbo-boost * Run `pyperf system tune` * Run benchmarks with CPU pinning |
|||
| msg379825 - (view) | Author: Tal Einat (taleinat) * |
Date: 2020-10-28 09:14 | |
I should also mention that I configured and compiled Python for each of the above-mentioned versions using the --enable-optimizations` flag. |
|||
| msg380473 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-11-06 20:28 | |
I am attempting to better understand the performance characteristics to determine where a cutoff should go. Attached is a colorful table of benchmarks of the existing algorithm to the PR with the cutoff changed to `if (1)` (always two-way) or `if (0)` (always status quo), and tested on a variety of needle lengths and haystack lengths. |
|||
| msg380474 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-11-06 20:31 | |
I used the following script, and the raw results are attached.
import pyperf
runner = pyperf.Runner()
ms = [12, 16, 24, 32, 48, 64, 96, 128,
192, 256, 384, 512, 768, 1024, 1536]
ns = [2000, 3000, 4000, 6000, 8000,
12000, 16000, 24000, 32000, 48000,
64000, 96000]
for n, m in product(ns, ms):
runner.timeit(f"needle={m}, haystack={n}",
setup="needle = zipf_string(m); haystack = zipf_string(n)",
stmt="needle in haystack",
globals=locals() | globals())
|
|||
| msg380476 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-11-06 21:28 | |
I'm sorry I haven't been able to give more time to this. I love what's been done, but am just overwhelmed :-( The main thing here is to end quadratic-time disasters, without doing significant damage in other cases. Toward that end it would be fine to use "very high" cutoffs, and save tuning for later. It's clear that we _can_ get significant benefit even in many non-disastrous cases, but unclear exactly how to exploit that. But marking the issue report as "fixed" doesn't require resolving that - and I want to see this improvement in the next Python release. An idea that hasn't been tried: in the world of sorting, quicksort is usually the fastest method - but it's prone to quadratic-time disasters. OTOH, heapsort never suffers disasters, but is almost always significantly slower in ordinary cases. So the more-or-less straightforward "introsort" compromises, by starting with a plain quicksort, but with "introspection" code added to measure how quickly it's making progress. If quicksort appears to be thrashing, it switches to heapsort. It's possible an "introsearch" would work well too. Start with pure brute force (not even with the current preprocessing), and switch to something else if it's making slow progress. That's easy to measure: compare the number of character comparisons we've made so far to how many character positions we've advanced the search window so far. If that ratio exceeds (say) 3, we're heading out of linear-time territory, so should switch to a different approach. With no preprocessing at all, that's likely to be faster than even the current code for very short needles, and in all cases where the needle is found at the start of the haystack. This context is trickier, though, in that the current code, and pure C&P, can also enjoy sub-linear time cases. It's always something ;-) |
|||
| msg380477 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2020-11-06 21:46 | |
But that also suggests a different approach: start with the current code, but add introspection to switch to your enhancement of C&P if the current code is drifting out of linear-time territory. |
|||
| msg380487 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-11-07 01:59 | |
> Toward that end it would be fine to use "very high" cutoffs, and save tuning for later. This feels reasonable to me -- I changed the cutoff to the more cautious `if (m >= 100 && n - m >= 5000)`, where the averages are very consistently faster by my measurements, and it seems that Tal confirms that, at least for the `m >= 100` part. More tuning may be worth exploring later, but this seems pretty safe for now, and it should fix all of the truly catastrophic cases like in the original post. |
|||
| msg382905 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2020-12-12 09:41 | |
For convenience, attached is a quick and dirty Tkinter GUI that lets you step through the Crochemore/Perrin Algorithm on your choice of inputs, just for play/discovery.
A good illustration of the memory for periodic needles can be found by testing:
haystack="456,123,123,456,123,123,456"
needle="123,123,123,"
The GUI program does not implement the Boyer-Moore/Horspool/Sunday-style shift-table. In the current PR 22904, this table is used in exactly those situations where the GUI says "Matched 0, so jump ahead by 1".
|
|||
| msg385169 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2021-01-17 22:56 | |
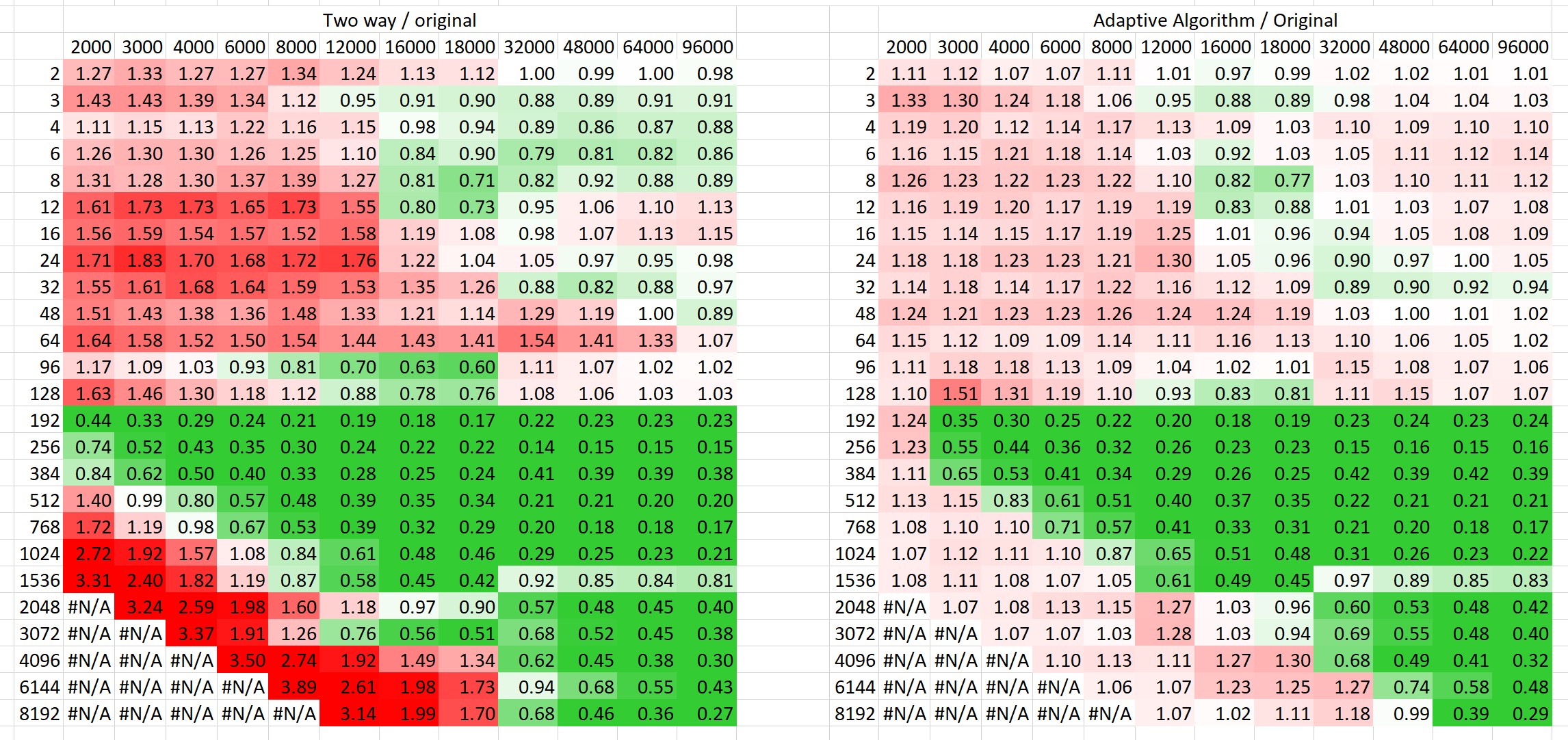
PR 22904 now adds a text document explaining how the Two-Way algorithm works in much more detail. I was looking at more benchmarking results, and I came to a couple of conclusions about cutoffs. There's a consistent benefit to using the two-way algorithm whenever both strings are long enough and the needle is less than 20% the length of the haystack. If that percentage is higher, the preprocessing cost starts to dominate, and the Two-Way algorithm is slower than the status quo in average such cases. This doesn't change the fact that in cases like OP's original example, the Two-way algorithm can be thousands of times faster than the status quo, even though the needle is a significant percentage of the length of the haystack. So to handle that, I tried an adaptive/introspective algorithm like Tim suggested: it counts the number of matched characters that don't lead to full matches, and once that total exceeds O(m), the Two-Way preprocessing cost will surely be worth it. The only way I could figure out how to not damage the speed of the usual small-string cases is to duplicate that code. See comparison.jpg for how much better the adaptive version is as opposed to always using two-way on this Zipf benchmark, while still guaranteeing O(m + n). |
|||
| msg387717 - (view) | Author: Carl Friedrich Bolz-Tereick (Carl.Friedrich.Bolz) * | Date: 2021-02-26 09:45 | |
> BTW, this initialization in the FASTSEARCH code appears to me to be a mistake: > skip = mlast - 1; Thanks for pointing that out Tim! Turns out PyPy had copied that mindlessly and I just fixed it. (I'm also generally following along with this issue, I plan to implement the two-way algorithm for PyPy as well, once you all have decided on a heuristic. We are occasionally in a slightly easier situation, because for constant-enough needles we can have the JIT do the pre-work on the needle during code generation.) |
|||
| msg387790 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2021-02-27 22:19 | |
Any chance PR 22904 can make it into 3.10 before the May 03 feature freeze? The text document in that PR has some notes on how the algorithm works, so that may be a good place to start reviewing if anyone is interested. |
|||
| msg387791 - (view) | Author: Guido van Rossum (gvanrossum) * |
Date: 2021-02-27 22:25 | |
If Tim approves we might get it into alpha 6 which goes out Monday. |
|||
| msg387792 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2021-02-27 22:32 | |
I'm very sorry for not keeping up with this - my health has been poor, and I just haven't been able to make enough time. Last time I looked to a non-trivial depth, I was quite happy, and just quibbling about possible tradeoffs. I can't honestly commit to doing better in the near future, so where does that leave us? I'd personally "risk it". I just added Raymond to the nosy list, on the off chance he can make some "emergency time" to give a more informed yes/no. He's routinely sucked up weeks of my life with random review requests, so I figure turnabout is fair play ;-) |
|||
| msg387813 - (view) | Author: Tim Peters (tim.peters) * |
Date: 2021-02-28 18:20 | |
New changeset 73a85c4e1da42db28e3de57c868d24a089b8d277 by Dennis Sweeney in branch 'master': bpo-41972: Use the two-way algorithm for string searching (GH-22904) https://github.com/python/cpython/commit/73a85c4e1da42db28e3de57c868d24a089b8d277 |
|||
| msg397277 - (view) | Author: Dennis Sweeney (Dennis Sweeney) * |
Date: 2021-07-12 03:57 | |
In "Fast String Searching" (1991), A. Hume and D. Sunday emphasize that most of the runtime of string-search algorithms occurs in a code path that skips over immediately-disqualified alignments. As such, that paper recommends extracting a hot "Horspool" code path and keeping it small. For that reason, I'm posting a PR which boils down that fast path to the following:
while (skip > 0 && window_last < haystack_end) {
window_last += skip;
skip = table[(*window_last) & 63];
}
This uses two memory accesses, whereas the last implementation used three (the extra to get window[cut]). This requires the skip table to change slightly, since it is indexed by the last character in the current haystack window rather than one character later ("fast" versus "sd1" in the paper). The paper also recommends unrolling this loop 3x, but my benchmarks found no benefit to unrolling.
The PR also refactors some of the main fastsearch code into separate functions, and computes and then uses a similar gap/skip integer used already in the default implementation (Hume and Sunday call this "md2"). It retains a linear-time constant space worst-case with the Two-Way algorithm.
There are a bunch of benchmarks here, both on Zipf-distributed random strings and on a few c/rst/python/binary files in the cpython repo. They compare the current main branch to the PR:
https://gist.github.com/sweeneyde/fc20ed5e72dc6b0f3b41c0abaf4ec3be
Summary of those results:
On the Zipf strings:
* 83 cases slower (at most 1.59x slower)
* 654 cases faster (up to 4.49x faster)
* Geometric mean: 1.10x faster
On the "Real world" source files:
* 76 cases slower (at most 2.41x slower)
* 420 cases faster (up to 18.12x faster)
* Geometric mean: 1.33x faster
|
|||
| msg397787 - (view) | Author: Łukasz Langa (lukasz.langa) * |
Date: 2021-07-19 10:57 | |
I checked the original example in this issue and the newest change in GH-27091 makes the `data.find(base)` case 8.2% faster compared to `main` while the `data.find(longer)` case is 10.8% faster. |
|||
| msg397788 - (view) | Author: Łukasz Langa (lukasz.langa) * |
Date: 2021-07-19 10:58 | |
New changeset d01dceb88b2ca6def8a2284e4c90f89a4a27823f by Dennis Sweeney in branch 'main': bpo-41972: Tweak fastsearch.h string search algorithms (GH-27091) https://github.com/python/cpython/commit/d01dceb88b2ca6def8a2284e4c90f89a4a27823f |
|||
| msg397805 - (view) | Author: Łukasz Langa (lukasz.langa) * |
Date: 2021-07-19 15:25 | |
Looks like this can be closed now, the original issue is fixed, the original patch is merged for 3.10, and the improved patch is merged for 3.11. Thanks! ✨ 🍰 ✨ |
|||
| History | |||
|---|---|---|---|
| Date | User | Action | Args |
| 2022-04-11 14:59:36 | admin | set | github: 86138 |
| 2021-07-19 15:25:54 | lukasz.langa | set | status: open -> closed resolution: fixed messages: + msg397805 stage: patch review -> resolved |
| 2021-07-19 10:58:44 | lukasz.langa | set | messages: + msg397788 |
| 2021-07-19 10:57:33 | lukasz.langa | set | nosy:
+ lukasz.langa messages: + msg397787 |
| 2021-07-12 03:57:27 | Dennis Sweeney | set | messages: + msg397277 |
| 2021-07-12 03:56:24 | Dennis Sweeney | set | pull_requests: + pull_request25639 |
| 2021-02-28 21:12:53 | Dennis Sweeney | set | pull_requests: + pull_request23457 |
| 2021-02-28 18:20:56 | tim.peters | set | messages: + msg387813 |
| 2021-02-27 22:32:12 | tim.peters | set | nosy:
+ rhettinger messages: + msg387792 |
| 2021-02-27 22:25:48 | gvanrossum | set | messages: + msg387791 |
| 2021-02-27 22:19:39 | Dennis Sweeney | set | messages: + msg387790 |
| 2021-02-26 09:45:39 | Carl.Friedrich.Bolz | set | nosy:
+ Carl.Friedrich.Bolz messages: + msg387717 |
| 2021-01-17 22:56:56 | Dennis Sweeney | set | files:
+ comparison.jpg messages: + msg385169 |
| 2020-12-13 01:35:39 | Dennis Sweeney | set | files: + twoway_demo.py |
| 2020-12-13 01:34:47 | Dennis Sweeney | set | files: - twoway_demo.py |
| 2020-12-12 09:41:34 | Dennis Sweeney | set | files:
+ twoway_demo.py messages: + msg382905 |
| 2020-11-09 14:55:36 | vstinner | set | nosy:
- vstinner |
| 2020-11-07 01:59:41 | Dennis Sweeney | set | messages: + msg380487 |
| 2020-11-06 21:46:13 | tim.peters | set | messages: + msg380477 |
| 2020-11-06 21:28:40 | tim.peters | set | messages: + msg380476 |
| 2020-11-06 20:31:37 | Dennis Sweeney | set | files:
+ length_benchmarks.txt messages: + msg380474 |
| 2020-11-06 20:28:21 | Dennis Sweeney | set | files:
+ Table of benchmarks on lengths.jpg messages: + msg380473 |
| 2020-10-28 09:14:22 | taleinat | set | messages: + msg379825 |
| 2020-10-28 08:15:32 | taleinat | set | files:
+ twoway-benchmark-results-2020-10-28.txt nosy: + taleinat messages: + msg379822 |
| 2020-10-23 23:14:13 | Dennis Sweeney | set | messages: + msg379494 |
| 2020-10-23 09:32:12 | Dennis Sweeney | set | messages: + msg379422 |
| 2020-10-23 01:10:10 | tim.peters | set | messages: + msg379391 |
| 2020-10-23 00:30:01 | Dennis Sweeney | set | messages: + msg379388 |
| 2020-10-23 00:03:26 | Dennis Sweeney | set | pull_requests: + pull_request21836 |
| 2020-10-19 18:28:25 | Dennis Sweeney | set | messages: + msg378979 |
| 2020-10-19 05:33:18 | tim.peters | set | messages: + msg378924 |
| 2020-10-19 05:16:16 | Dennis Sweeney | set | messages: + msg378923 |
| 2020-10-19 04:55:36 | Dennis Sweeney | set | messages: + msg378922 |
| 2020-10-19 03:43:38 | tim.peters | set | messages: + msg378920 |
| 2020-10-19 01:30:37 | Dennis Sweeney | set | messages: + msg378917 |
| 2020-10-19 01:24:36 | Dennis Sweeney | set | messages: + msg378916 |
| 2020-10-18 02:09:49 | tim.peters | set | messages: + msg378847 |
| 2020-10-18 01:45:41 | gvanrossum | set | messages: + msg378844 |
| 2020-10-18 01:04:29 | tim.peters | set | messages: + msg378843 |
| 2020-10-18 00:12:43 | gvanrossum | set | nosy:
+ gvanrossum messages: + msg378842 |
| 2020-10-17 21:35:10 | Dennis Sweeney | set | messages: + msg378836 |
| 2020-10-17 20:51:12 | tim.peters | set | messages: + msg378834 |
| 2020-10-17 20:25:18 | Dennis Sweeney | set | messages: + msg378828 |
| 2020-10-16 23:50:15 | tim.peters | set | messages: + msg378793 |
| 2020-10-16 21:13:06 | tim.peters | set | type: behavior -> performance messages: + msg378753 |
| 2020-10-16 21:11:19 | tim.peters | set | messages:
+ msg378751 versions: - Python 3.8 |
| 2020-10-16 21:08:45 | tim.peters | set | messages: + msg378750 |
| 2020-10-16 19:52:44 | gregory.p.smith | set | messages: + msg378742 |
| 2020-10-16 19:39:52 | Dennis Sweeney | set | messages: + msg378739 |
| 2020-10-16 19:17:43 | gregory.p.smith | set | messages: + msg378737 |
| 2020-10-16 19:14:38 | gregory.p.smith | set | messages: + msg378736 |
| 2020-10-14 21:14:17 | Dennis Sweeney | set | messages: + msg378652 |
| 2020-10-14 16:20:16 | tim.peters | set | messages: + msg378635 |
| 2020-10-14 05:54:04 | gregory.p.smith | set | nosy:
+ gregory.p.smith |
| 2020-10-14 03:03:55 | tim.peters | set | messages: + msg378600 |
| 2020-10-14 01:06:06 | tim.peters | set | messages: + msg378590 |
| 2020-10-13 22:56:10 | Dennis Sweeney | set | messages: + msg378585 |
| 2020-10-13 22:51:18 | Dennis Sweeney | set | messages: + msg378584 |
| 2020-10-13 22:47:20 | Dennis Sweeney | set | messages: + msg378583 |
| 2020-10-13 22:03:35 | tim.peters | set | messages: + msg378582 |
| 2020-10-13 21:42:49 | Dennis Sweeney | set | files:
+ bench_table.txt messages: + msg378579 |
| 2020-10-13 21:30:39 | tim.peters | set | messages: + msg378578 |
| 2020-10-13 21:04:17 | vstinner | set | messages: + msg378576 |
| 2020-10-13 13:57:04 | corona10 | set | nosy:
+ corona10 |
| 2020-10-13 11:42:16 | vstinner | set | messages: + msg378556 |
| 2020-10-13 07:13:44 | vstinner | set | messages: + msg378543 |
| 2020-10-13 07:06:15 | vstinner | set | messages: + msg378541 |
| 2020-10-12 23:55:51 | Dennis Sweeney | set | files:
+ random_bench.py messages: + msg378537 |
| 2020-10-12 23:50:35 | Dennis Sweeney | set | files:
+ bench_results.txt messages: + msg378534 |
| 2020-10-12 23:43:33 | Dennis Sweeney | set | stage: patch review pull_requests: + pull_request21650 |
| 2020-10-12 07:00:37 | Dennis Sweeney | set | files:
+ fastsearch.h messages: + msg378472 |
| 2020-10-12 05:06:35 | tim.peters | set | messages: + msg378470 |
| 2020-10-11 06:51:33 | Dennis Sweeney | set | files:
+ fastsearch.py messages: + msg378423 |
| 2020-10-11 03:37:47 | tim.peters | set | messages: + msg378420 |
| 2020-10-10 08:25:19 | Dennis Sweeney | set | messages: + msg378372 |
| 2020-10-09 14:56:05 | tim.peters | set | files:
+ fastsearch.diff keywords: + patch messages: + msg378329 |
| 2020-10-09 03:53:47 | tim.peters | set | messages: + msg378301 |
| 2020-10-08 18:01:24 | tim.peters | set | messages: + msg378263 |
| 2020-10-08 17:31:43 | tim.peters | set | messages: + msg378260 |
| 2020-10-08 11:06:59 | Dennis Sweeney | set | files:
+ reproducer.py messages: + msg378233 |
| 2020-10-08 09:59:28 | vstinner | set | nosy:
+ vstinner messages: + msg378229 |
| 2020-10-08 09:09:01 | Dennis Sweeney | set | nosy:
+ Dennis Sweeney messages: + msg378225 |
| 2020-10-08 08:03:49 | ammar2 | set | nosy:
+ ammar2 messages: + msg378222 |
| 2020-10-08 07:58:10 | serhiy.storchaka | set | nosy:
+ serhiy.storchaka messages: + msg378221 versions: + Python 3.10 |
| 2020-10-08 04:52:11 | pmpp | set | nosy:
+ pmpp |
| 2020-10-08 03:21:01 | tim.peters | set | nosy:
+ tim.peters messages: + msg378210 |
| 2020-10-08 03:14:02 | josh.r | set | type: performance -> behavior |
| 2020-10-08 03:12:08 | josh.r | set | nosy:
+ josh.r messages: + msg378209 |
| 2020-10-07 23:31:59 | Zeturic | create | |