|
|
msg375089 - (view) |
Author: Raymond Hettinger (rhettinger) *  |
Date: 2020-08-10 01:14 |
I'd like to resurrect Serhiy's idea for using power-of-two scaling in math.hypot() rather than dividing each coordinate by the maximum value.
I drafted a patch. It looks to be a little faster than what we have now and is generally (but not always) more accurate.
For accuracy, the current approach has the advantage that for the largest coordinate, (x/max)**2 is exactly 1.0. If that element is much larger than the others, it overpowers the 1/2 ulp error in each of the other divisions.
In contrast, scaling by a power of two is always exact, but the squaring of the largest scaled coordinate is no longer exact.
The two approaches each have some cases that are more accurate than the other. I generated 10,000 samples. In 66% of the cases, the two results agree. In 26% of the cases, scaling by a power of two was more accurate. In the remaining 8%, the division by max was more accurate. The standard deviation of relative errors was better using power-of-two scaling. These results were consistent whether using 2, 3, or 20 dimensions.
As expected, multiplying by a power of two was a bit faster than dividing by an arbitrary float.
|
|
msg375096 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-10 05:00 |
Added a revised script for testing accuracy measured in ULPs. It shows an improvement for all dimensions tested, with the best for 2 dimensions. Also, the maximum error is now 1 ulp; formerly, it was 2 ulps.
======== 2 dimensions ========
div-by-max: [(-2.0, 14), (-1.0, 1721), (0.0, 6533), (1.0, 1722), (2.0, 10)]
scaled-by-2: [(-1.0, 841), (0.0, 8339), (1.0, 820)]
======== 3 dimensions ========
div-by-max: [(-2.0, 3), (-1.0, 1525), (0.0, 6933), (1.0, 1535), (2.0, 4)]
scaled-by-2: [(-1.0, 739), (0.0, 8515), (1.0, 746)]
======== 5 dimensions ========
div-by-max: [(-2.0, 2), (-1.0, 1377), (0.0, 7263), (1.0, 1358)]
scaled-by-2: [(-1.0, 695), (0.0, 8607), (1.0, 698)]
======== 10 dimensions ========
div-by-max: [(-2.0, 13), (-1.0, 1520), (0.0, 6873), (1.0, 1580), (2.0, 14)]
scaled-by-2: [(-1.0, 692), (0.0, 8605), (1.0, 703)]
======== 20 dimensions ========
div-by-max: [(-1.0, 1285), (0.0, 7310), (1.0, 1405)]
scaled-by-2: [(-1.0, 555), (0.0, 8822), (1.0, 623)]
|
|
msg375166 - (view) |
Author: Mark Dickinson (mark.dickinson) * |
Date: 2020-08-11 07:50 |
Fine by me in principle; I haven't had a chance to look at the code yet.
While we're doing this, any chance we could special-case the two-argument hypot to use the libm hypot directly? On many platforms the libm hypot will be correctly rounded, or close to it. There was a noticeable accuracy regression for two-argument hypot when hypot gained the ability to support multiple arguments.
|
|
msg375437 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-14 22:54 |
> While we're doing this, any chance we could special-case
> the two-argument hypot to use the libm hypot directly?
Yes, that is an easy amendment (see below).
I just tried it out on the macOs build but didn't see a change in accuracy from the current PR which uses lossless power-of-two-scaling and Neumaier summation.
In GCC's libquadmath implementation, the comments say that the error is less than 1 ulp, falling short of being correctly rounded within ±½ ulp.
If the platform hypots have the nearly the same accuracy as the current PR, it may make sense to skip the special case and opt for consistent cross-platform results.
==================================================================
$ git diff
diff --git a/Modules/mathmodule.c b/Modules/mathmodule.c
index d0621f59df..3a42ea5318 100644
--- a/Modules/mathmodule.c
+++ b/Modules/mathmodule.c
@@ -2457,6 +2457,10 @@ vector_norm(Py_ssize_t n, double *vec, double max, int found_nan)
if (max == 0.0 || n <= 1) {
return max;
}
+ if (n == 2) {
+ /* C library hypot() implementations tend to be very accurate */
+ return hypot(vec[0], vec[1]);
+ }
frexp(max, &max_e);
if (max_e >= -1023) {
scale = ldexp(1.0, -max_e)
$ gcc --version
Configured with: --prefix=/Applications/Xcode.app/Contents/Developer/usr --with-gxx-include-dir=/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include/c++/4.2.1
Apple clang version 11.0.3 (clang-1103.0.32.62)
Target: x86_64-apple-darwin19.6.0
Thread model: posix
InstalledDir: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin
$ ./python.exe test_hypot.py
======== 2 dimensions ========
platform hypot(): [(-1.0, 8398), (0.0, 83152), (1.0, 8450)]
scaled-by-2 : [(-1.0, 8412), (0.0, 83166), (1.0, 8422)]
|
|
msg375440 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-14 23:29 |
This paper addresses the topic directly: https://arxiv.org/pdf/1904.09481.pdf
I tried to reproduce the results shown in Table 1 of the paper. For clib hypot(), they get 1 ulp errors 12.91% of the time. On my build, using the same gaussian distribution, I get 14.08% for both the clang hypot() and for the current version of the PR, showing that the two are fundamentally the same.
|
|
msg375442 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-15 00:51 |
Per the referenced paper, here's what is involved in further reducing error:
def hypot(*coords):
# Corrected, unfused: https://arxiv.org/pdf/1904.09481.pdf
# Simplified version omits scaling and handling of wide ranges.
# Only handle the 2-dimensional cases.
# Has 1 ulp error 0.88% of the time (0.54% per the paper).
# Can be reduced to 0.00% with a reliable fused multiply-add.
a, b = map(fabs, coords)
h = sqrt(a*a + b*b)
if h <= 2*b:
delta = h - b
x = a*(2*delta - a) + (delta - 2*(a - b))*delta
else:
delta = h - a
x = 2*delta*(a - 2*b) + (4*delta - b)*b + delta*delta
return h - x/(2*h)
|
|
msg375447 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-15 04:54 |
Update:
def hypot(*coords):
# Corrected, unfused: https://arxiv.org/pdf/1904.09481.pdf
# Simplified version omits scaling and handling of wide ranges
# Has 1 ulp error 0.44% of the time (0.54% per the paper).
# Can be reduced to 0% with a fused multiply-add.
a, b = map(fabs, coords)
if a < b:
a, b = b, a
h = sqrt(a*a + b*b)
if h <= 2*b:
delta = h - b
x = a*(2*delta - a) + (delta - 2*(a - b))*delta
else:
delta = h - a
x = 2*delta*(a - 2*b) + (4*delta - b)*b + delta*delta
return h - x/(2*h)
|
|
msg375448 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2020-08-15 05:03 |
Cute: for any number of arguments, try computing h**2, then one at a time subtract a**2 (an argument squared) in descending order of magnitude. Call that (h**2 - a1**2 - a2**2 - ...) x.
Then
h -= x/(2*h)
That should reduce errors too, although not nearly so effectively, since it's a cheap way of estimating (& correcting for) the discrepancy between sum(a**2) and h**2.
Note that "descending order" is important: it's trying to cancel as many leading bits as possible as early as possible, so that lower-order bits come into play.
Then again ... why bother? ;-)
|
|
msg375483 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2020-08-15 17:44 |
> ...
> one at a time subtract a**2 (an argument squared) in descending
> order of magnitude
> ...
But that doesn't really help unless the sum of squares was computed without care to begin with. Can do as well by skipping that but instead computing the original sum of squares in increasing order of magnitude.
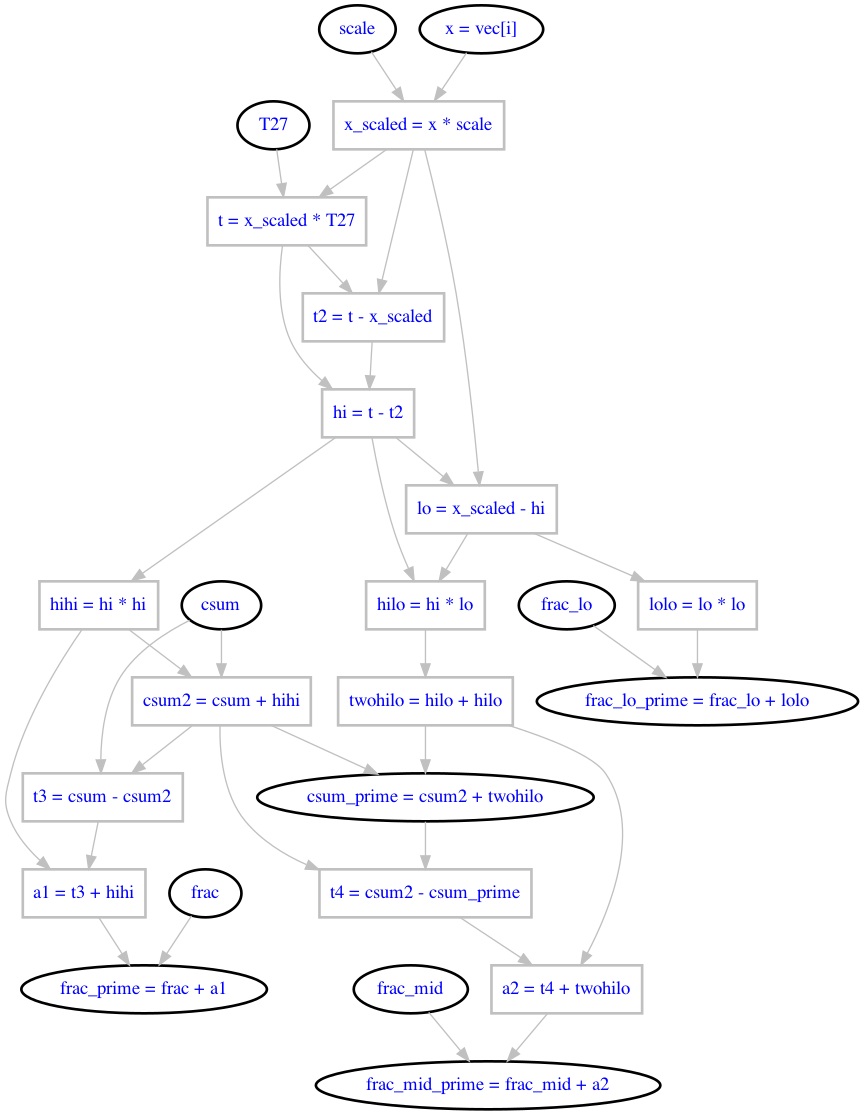
Cheapest way I know of that "seemingly always" reproduces the Decimal result (when that's rounded back to float) combines fsum(), Veltkamp splitting, and the correction trick from the paper:
def split(x, T27=ldexp(1.0, 27)+1.0):
t = x * T27
hi = t - (t - x)
lo = x - hi
assert hi + lo == x
return hi, lo
# result := hypot(*xs)
parts = []
for x in xs:
a, b = split(x)
parts.append(a*a)
parts.append(2.0*a*b)
parts.append(b*b)
result = sqrt(fsum(parts))
a, b = split(result)
parts.append(-a*a)
parts.append(-2.0*a*b)
parts.append(-b*b)
x = fsum(parts) # best float approx to sum(x_i ** 2) - result**2
result += x / (2.0 * result)
|
|
msg375489 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-15 18:37 |
> Cheapest way I know of that "seemingly always" reproduces
> the Decimal result (when that's rounded back to float)
> combines fsum(), Veltkamp splitting, and the correction
> trick from the paper.
That's impressive. Do you think this is worth implementing? Or should we declare victory with the current PR which is both faster and more accurate than what we have now?
Having 1-ulp error 17% of the time and correctly rounded 83% of the time is pretty darned good (and on par with C library code for the two-argument case).
Unless we go all-out with the technique you described, the paper shows that we're already near the limit of what can be done by trying to make the sum of squares more accurate, "... the correctly rounded square root of the correctly rounded a**2+b**2 can still be off by as much as one ulp. This hints at the possibility that working harder to compute a**2+b**2 accurately may not be the best path to a better answer".
FWIW, in my use cases, the properties that matter most are monotonicity, commutativity, cross-platform portability, and speed. Extra accuracy would nice to have but isn't essential and would likely never be noticed.
|
|
msg375498 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2020-08-16 01:40 |
Oh no - I wouldn't use this as a default implementation. Too expensive. There is one aspect you may find especially attractive, though: unlike even the Decimal approach, it should be 100% insensitive to argument order (no info is lost before fsum() is called, and fsum's output should be unaffected by summand order).
|
|
msg375500 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-16 02:38 |
New changeset fff3c28052e6b0750d6218e00acacd2fded4991a by Raymond Hettinger in branch 'master':
bpo-41513: Improve speed and accuracy of math.hypot() (GH-21803)
https://github.com/python/cpython/commit/fff3c28052e6b0750d6218e00acacd2fded4991a
|
|
msg375501 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-16 02:42 |
If someone thinks there is a case for using the C library hypot() for the two-argument form, feel free to reopen this.
Likewise, if someone thinks there is a case for doing the expensive but more accurate algorithm, go ahead and reopen this.
Otherwise, I think we're done for now :-)
|
|
msg375591 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-18 04:48 |
Here's a much cheaper way to get correctly rounded results almost all of the time. It uses Serhiy's idea for scaling by a power of two, Tim's idea for Veltkamp-Dekker splitting, my variant of Neumaier summation, and the paper's differential correction. Together, these allow the algorithm to simulate 128-bit quad precision throughout.
# Veltkamp-Dekker splitting
def split(x, T27=ldexp(1.0, 27)+1.0):
t = x * T27
hi = t - (t - x)
lo = x - hi
assert hi + lo == x
return hi, lo
# Variant of Neumaier summation specialized
# for cases where |csum| >= |x| for every x.
# Establishes the invariant by setting *csum*
# to 1.0, only adding *x* values of smaller
# magnitude, and subtracting 1.0 at the end.
def zero():
return 1.0, 0.0 # csum, frac
def add_on(x, state):
csum, frac = state
assert fabs(csum) >= fabs(x)
oldcsum = csum
csum += x
frac += (oldcsum - csum) + x
return csum, frac
def to_float(state):
csum, frac = state
return csum - 1.0 + frac
def hypot(*xs):
max_value = max(xs, key=fabs)
_, max_e = frexp(max_value)
scalar = ldexp(1.0, -max_e)
parts = zero()
for x in xs:
x *= scalar
a, b = split(x)
parts = add_on(a*a, parts)
parts = add_on(2.0*a*b, parts)
parts = add_on(b*b, parts)
result = sqrt(to_float(parts))
a, b = split(result)
parts = add_on(-a*a, parts)
parts = add_on(-2.0*a*b, parts)
parts = add_on(-b*b, parts)
x = to_float(parts) # best float approx to sum(x_i ** 2) - result**2
result += x / (2.0 * result)
return result / scalar
|
|
msg375600 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-18 08:43 |
Hmm, I tried-out a C implementation and the timings weren't bad, 60% slower in exchange for always being correctly rounded. Do you all think that would be worth it?
# New correctly rounded
$ ./python.exe -m timeit -r11 -s 'from math import hypot' 'hypot(1.7, 15.5, 0.3, 5.2)'
2000000 loops, best of 11: 101 nsec per loop
$ ./python.exe -m timeit -r11 -s 'from math import hypot' 'hypot(1.7, 15.81)'
5000000 loops, best of 11: 82.8 nsec per loop
# Current baseline for Python 3.10
$ ./python.exe -m timeit -r11 -s 'from math import hypot' 'hypot(1.7, 15.5, 0.3, 5.2)'
5000000 loops, best of 11: 65.6 nsec per loop
$ ./python.exe -m timeit -r11 -s 'from math import hypot' 'hypot(1.7, 15.81)'
5000000 loops, best of 11: 56.6 nsec per loop
# Current baseline for Python 3.9
$ ./python.exe -m timeit -r11 -s 'from math import hypot' 'hypot(1.7, 15.5, 0.3, 5.2)'
5000000 loops, best of 11: 72.2 nsec per loop
~/npython $ ./python.exe -m timeit -r11 -s 'from math import hypot' 'hypot(1.7, 15.81)'
5000000 loops, best of 11: 56.2 nsec per loop
|
|
msg375623 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2020-08-18 18:29 |
About speed, the fsum() version I posted ran about twice as fast as the all-Decimal approach, but the add_on() version runs a little slower than all-Decimal. I assume that's because fsum() is coded in C while the add_on() prototype makes mounds of additional Python-level function calls. Using released Windows 3.8.5 CPython and on argument vectors of length 50.
Is it worth it? Up to you ;-) There are good arguments to be made in favor of increased accuracy, and in favor of speed.
About "correctly rounded", such a claim can only be justified by proof, not by testing (unless testing exhaustively covers the entire space of inputs). Short of that, best you can claim is stuff like "max error < 0.51 ulp" (or whatever other bound can be proved).
|
|
msg375634 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2020-08-19 03:46 |
Here's a "correct rounding" fail for the add_on approach:
xs = [16.000000000000004] * 9
decimal result = 48.00000000000001065814103642
which rounds to float 48.000000000000014
add_on result: 48.00000000000001
That's about 0.5000000000026 ulp too small - shocking ;-)
The fsum approach got this one right, but has similar failures on other inputs of the same form; i.e.,
[i + ulp(i)] * 9
for various integers `i`.
|
|
msg375635 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2020-08-19 05:00 |
> That's about 0.5000000000026 ulp too small - shocking ;-)
Actually, that's an illusion due to the limited precision of Decimal. The rounded result is exactly 1/2 ulp away from the infinitely precise result - it's a nearest/even tie case.
To make analysis easy, just note that the mathematical hypot(*([x] * 9)) is exactly 3*x. For x = 16 + ulp(16), 3*x moves to a higher binade and has two trailing one bits. The last has to be rounded away, rounding up to leave the last retained bit even. Any source of error, no matter how tiny, can be enough so that doesn't happen.
|
|
msg375651 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2020-08-19 15:10 |
Here's an amusing cautionary tale: when looking at correct-rounding failures for the fsum approach, I was baffled until I realized it was actually the _decimal_ method that was failing. Simplest example I have is 9 instances of b=4.999999999999999, which is 1 ulp less than 5. Of course the best-possible hypot is 3*b rounded, but that's not what default decimal precision computes (when rounded back). In fact, it bounces between "off by 1" and "correct" until decimal precision exceeds 96:
>>> pfailed = []
>>> for p in range(28, 300):
... with decimal.localcontext() as c:
... c.prec = p
... if float(sum([decimal.Decimal(b) ** 2] * 9).sqrt()) != 3*b:
... pfailed.append(p)
>>> pfailed
[28, 29, 30, 31, 34, 36, 37, 39, 41, 42, 43, 44, 45, 57, 77, 96]
In a nutshell, it takes in the ballpark of 50 decimal digits to represent b exactly, then twice as many to represent its square exactly, then another to avoid losing a digit when summing 9 of those. So if decimal prec is less than about 100, it can lose info.
So the fsum method is actually more reliable (it doesn't lose any info until the fsum step).
|
|
msg375685 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2020-08-20 04:21 |
Just FYI, if the "differential correction" step seems obscure to anyone, here's some insight, following a chain of mathematical equivalent respellings:
result + x / (2 * result) =
result + (sumsq - result**2) / (2 * result) =
result + (sumsq - result**2) / result / 2 =
result + (sumsq / result - result**2 / result) / 2 =
result + (sumsq / result - result) / 2 =
result + sumsq / result / 2 - result / 2 =
result / 2 + sumsq / result / 2 =
(result + sumsq / result) / 2
I hope the last line is an "aha!" for you then: it's one iteration of Newton's square root method, for improving a guess "result" for the square root of "sumsq". Which shouldn't be too surprising, since Newton's method is also derived from a first-order Taylor expansion around 0.
Note an implication: the quality of the initial square root is pretty much irrelevant, since a Newton iteration basically doubles the number of "good bits". Pretty much the whole trick relies on computing "sumsq - result**2" to greater than basic machine precision.
|
|
msg375721 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2020-08-20 16:26 |
My apologies if nobody cares about this ;-) I just think it's helpful if we all understand what really helps here.
> Pretty much the whole trick relies on computing
> "sumsq - result**2" to greater than basic machine
> precision.
But why is that necessary at all? Because we didn't compute the sqrt of the sum of the squares to begin with - the input to sqrt was a _rounded_-to-double approximation to the sum of squares. The correction step tries to account for the sum-of-squares bits sqrt() didn't see to begin with.
So, e.g., instead of doing
result = sqrt(to_float(parts))
a, b = split(result)
parts = add_on(-a*a, parts)
parts = add_on(-b*b, parts)
parts = add_on(-2.0*a*b, parts)
x = to_float(parts)
result += x / (2.0 * result)
it works just as well to do just
result = float((D(parts[0] - 1.0) + D(parts[1])).sqrt())
where D is the default-precision decimal.Decimal constructor. Then sqrt sees all the sum-of-squares bits we have (although the "+" rounds away those following the 28th decimal digit).
|
|
msg375762 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-21 17:11 |
> My apologies if nobody cares about this ;-)
I care :-)
Am in crunch right now, so won't have a chance to work through it for a week or so.
|
|
msg375763 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2020-08-21 17:28 |
> won't have a chance to work through it for a week or so
These have been much more in the way of FYI glosses. There's no "suggestion" here to be pursued - just trying to get a deeper understanding of code already written :-)
While I can concoct any number of cases where the add_on() method fails correct rounding, all the ones I dug into turned out to be "oops! went the wrong way" in nearest/even tie cases. By any non-anal measure, its accuracy is excellent.
|
|
msg375770 - (view) |
Author: Terry J. Reedy (terry.reedy) * |
Date: 2020-08-21 21:54 |
Tim, I have been reading this, without examining all the details, to learn more about FP accuracy problems.
|
|
msg375829 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-23 23:11 |
I'm ready to move forward on this one. Have improved the assertions, explanations, and variable names. Hve also added references to show that the foundations are firm. After tens of millions of trials, I haven't found a single misrounding. I can't prove "correctly rounded" but am content with "high accuracy". The speed is comparable to what we had in 3.7, so I think it is a net win all around.
|
|
msg375865 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-24 23:56 |
All the review comments have been addressed. I think it is a good as it can get. Any objections to committing the PR?
|
|
msg375866 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2020-08-24 23:58 |
Do it! It's elegant and practical :-)
|
|
msg375867 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-25 00:40 |
New changeset 8e19c8be87017f6bef8e4c936b1e6ddacb558ad2 by Raymond Hettinger in branch 'master':
bpo-41513: More accurate hypot() (GH-21916)
https://github.com/python/cpython/commit/8e19c8be87017f6bef8e4c936b1e6ddacb558ad2
|
|
msg375868 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-25 00:41 |
Done!
Thank you.
|
|
msg375896 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2020-08-25 20:03 |
One more implication: since the quality of the initial square root doesn't really much matter, instead of
result = sqrt(to_float(parts))
a, b = split(result)
parts = add_on(-a*a, parts)
parts = add_on(-2.0*a*b, parts)
parts = add_on(-b*b, parts)
x = to_float(parts)
result += x / (2.0 * result)
at the end, it should work just as well (in fact, probably a little better, due to getting more beneficial cancellation) to do:
a = parts[0] - 1.0
result = sqrt(a)
x, y = split(result)
result += (a - x*x - 2.0*x*y - y*y + parts[1]) / (2.0 * result)
at the end. Although this crucially relies on the doing the last-line chain of subtracts and adds "left to right".
|
|
msg376068 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-08-29 16:11 |
New changeset 27de28607a248e5ffb8838162fca466a58c2e284 by Raymond Hettinger in branch 'master':
bpo-41513: Save unnecessary steps in the hypot() calculation (#21994)
https://github.com/python/cpython/commit/27de28607a248e5ffb8838162fca466a58c2e284
|
|
msg376098 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2020-08-30 05:22 |
About test_frac.py, I changed the main loop like so:
got = [float(expected)] # NEW
for hypot in hypots:
actual = hypot(*coords)
got.append(float(actual)) # NEW
err = (actual - expected) / expected
bits = round(1 / err).bit_length()
errs[hypot][bits] += 1
if len(set(got)) > 1: # NEW
print(got) # NEW
That is, to display every case where the four float results weren't identical.
Result: nothing was displayed (although it's still running the n=1000 chunk, there's no sign that will change). None of these variations made any difference to results users actually get.
Even the "worst" of these reliably develops dozens of "good bits" beyond IEEE double precision, but invisibly (under the covers, with no visible effect on delivered results).
So if there's something else that speeds the code, perhaps it's worth pursuing, but we're already long beyond the point of getting any payback for pursuing accuracy.
|
|
msg376470 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-09-06 22:10 |
New changeset 67c998de24985b36498b0fdac68d1beceb43aba7 by Raymond Hettinger in branch 'master':
bpo-41513: Expand comments and add references for a better understanding (GH-22123)
https://github.com/python/cpython/commit/67c998de24985b36498b0fdac68d1beceb43aba7
|
|
msg376869 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-09-14 06:33 |
New changeset 457d4e97de0369bc786e363cb53c7ef3276fdfcd by Raymond Hettinger in branch 'master':
bpo-41513: Add docs and tests for hypot() (GH-22238)
https://github.com/python/cpython/commit/457d4e97de0369bc786e363cb53c7ef3276fdfcd
|
|
msg376910 - (view) |
Author: STINNER Victor (vstinner) * |
Date: 2020-09-14 21:55 |
Multiple tests failed on x86 Gentoo Non-Debug with X 3.x:
https://buildbot.python.org/all/#/builders/58/builds/73
Example of failure:
======================================================================
FAIL: testHypotAccuracy (test.test_math.MathTests) (hx='0x1.10106eb4b44a2p+29', hy='0x1.ef0596cdc97f8p+29')
----------------------------------------------------------------------
Traceback (most recent call last):
File "/buildbot/buildarea/cpython/3.x.ware-gentoo-x86.nondebug/build/Lib/test/test_math.py", line 855, in testHypotAccuracy
self.assertEqual(hypot(x, y), z)
AssertionError: 1184594898.793983 != 1184594898.7939832
(I didn't investigate the bug, I just report the failure.)
|
|
msg376919 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-09-15 00:14 |
New changeset 95a8a0e01d1f4f49ad6b4d4f2ae3bbf93c462013 by Raymond Hettinger in branch 'master':
bpo-41513: Remove broken tests that fail on Gentoo (GH-22249)
https://github.com/python/cpython/commit/95a8a0e01d1f4f49ad6b4d4f2ae3bbf93c462013
|
|
msg376920 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-09-15 00:15 |
I saw that the Gentoo bot reacted badly to the new tests, so I reverted them.
|
|
msg377242 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-09-21 04:48 |
New changeset bc6b7fa6d7fb8957eb4ff809366af40dfb12b8cd by Raymond Hettinger in branch 'master':
bpo-41513: Add accuracy tests for math.hypot() (GH-22327)
https://github.com/python/cpython/commit/bc6b7fa6d7fb8957eb4ff809366af40dfb12b8cd
|
|
msg377354 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2020-09-23 03:01 |
New changeset 438e9fc66f664eff0526a16a6d900349bfd1f9d2 by Raymond Hettinger in branch 'master':
bpo-41513: Improve order of adding fractional values. Improve variable names. (GH-22368)
https://github.com/python/cpython/commit/438e9fc66f664eff0526a16a6d900349bfd1f9d2
|
|
| Date |
User |
Action |
Args |
| 2022-04-11 14:59:34 | admin | set | github: 85685 |
| 2020-10-02 00:19:15 | rhettinger | set | files:
+ best_frac.py |
| 2020-10-02 00:10:28 | rhettinger | set | files:
- best_frac.py |
| 2020-09-23 03:01:31 | rhettinger | set | messages:
+ msg377354 |
| 2020-09-23 00:55:51 | rhettinger | set | pull_requests:
+ pull_request21407 |
| 2020-09-21 04:48:03 | rhettinger | set | messages:
+ msg377242 |
| 2020-09-19 18:44:40 | rhettinger | set | pull_requests:
+ pull_request21371 |
| 2020-09-19 00:24:12 | rhettinger | set | pull_requests:
+ pull_request21360 |
| 2020-09-15 00:15:26 | rhettinger | set | status: open -> closed
resolution: fixed
messages:
+ msg376920
stage: patch review -> resolved |
| 2020-09-15 00:14:05 | rhettinger | set | messages:
+ msg376919 |
| 2020-09-14 22:01:58 | rhettinger | set | stage: resolved -> patch review
pull_requests:
+ pull_request21305 |
| 2020-09-14 21:55:38 | vstinner | set | status: closed -> open
nosy:
+ vstinner
messages:
+ msg376910
resolution: fixed -> (no value) |
| 2020-09-14 06:33:48 | rhettinger | set | messages:
+ msg376869 |
| 2020-09-14 05:21:28 | rhettinger | set | pull_requests:
+ pull_request21293 |
| 2020-09-06 22:10:16 | rhettinger | set | messages:
+ msg376470 |
| 2020-09-06 21:13:09 | rhettinger | set | pull_requests:
+ pull_request21207 |
| 2020-09-06 19:50:03 | rhettinger | set | files:
+ test_hypot_commutativity.py |
| 2020-09-06 19:49:13 | rhettinger | set | files:
- test_hypot_commutativity.py |
| 2020-09-02 22:13:00 | rhettinger | set | files:
+ hypot.png |
| 2020-09-02 22:12:44 | rhettinger | set | files:
- hypot.svg |
| 2020-09-02 18:39:10 | rhettinger | set | files:
+ hypot.svg |
| 2020-08-31 18:30:12 | rhettinger | set | pull_requests:
+ pull_request21130 |
| 2020-08-30 05:22:04 | tim.peters | set | messages:
+ msg376098 |
| 2020-08-30 03:21:39 | rhettinger | set | pull_requests:
+ pull_request21113 |
| 2020-08-30 02:58:02 | rhettinger | set | files:
+ best_frac.py |
| 2020-08-29 16:11:07 | rhettinger | set | messages:
+ msg376068 |
| 2020-08-28 22:06:38 | rhettinger | set | pull_requests:
+ pull_request21100 |
| 2020-08-25 20:03:54 | tim.peters | set | messages:
+ msg375896 |
| 2020-08-25 00:41:44 | rhettinger | set | status: open -> closed
resolution: fixed
messages:
+ msg375868
stage: patch review -> resolved |
| 2020-08-25 00:40:31 | rhettinger | set | messages:
+ msg375867 |
| 2020-08-24 23:58:15 | tim.peters | set | messages:
+ msg375866 |
| 2020-08-24 23:56:45 | rhettinger | set | messages:
+ msg375865 |
| 2020-08-24 18:44:53 | rhettinger | set | files:
+ hypot_flow.pdf |
| 2020-08-23 23:11:17 | rhettinger | set | messages:
+ msg375829
title: Scale by power of two in math.hypot() -> High accuracy math.hypot() |
| 2020-08-23 23:09:10 | rhettinger | set | messages:
- msg375827 |
| 2020-08-23 21:42:21 | rhettinger | set | priority: low -> normal
resolution: fixed -> (no value)
messages:
+ msg375827
|
| 2020-08-21 21:54:32 | terry.reedy | set | nosy:
+ terry.reedy
messages:
+ msg375770
|
| 2020-08-21 17:28:02 | tim.peters | set | messages:
+ msg375763 |
| 2020-08-21 17:11:13 | rhettinger | set | messages:
+ msg375762 |
| 2020-08-20 16:26:50 | tim.peters | set | messages:
+ msg375721 |
| 2020-08-20 04:21:55 | tim.peters | set | messages:
+ msg375685 |
| 2020-08-19 15:10:54 | tim.peters | set | messages:
+ msg375651 |
| 2020-08-19 05:00:59 | tim.peters | set | messages:
+ msg375635 |
| 2020-08-19 03:46:08 | tim.peters | set | messages:
+ msg375634 |
| 2020-08-18 18:29:16 | tim.peters | set | messages:
+ msg375623 |
| 2020-08-18 08:54:23 | rhettinger | set | stage: resolved -> patch review
pull_requests:
+ pull_request21032 |
| 2020-08-18 08:43:35 | rhettinger | set | status: closed -> open
messages:
+ msg375600 |
| 2020-08-18 04:48:30 | rhettinger | set | messages:
+ msg375591 |
| 2020-08-16 03:12:50 | rhettinger | set | files:
+ test_hypot_accuracy.py |
| 2020-08-16 02:53:02 | rhettinger | set | files:
+ test_hypot_commutativity.py |
| 2020-08-16 02:42:31 | rhettinger | set | status: open -> closed
resolution: fixed
messages:
+ msg375501
stage: patch review -> resolved |
| 2020-08-16 02:38:25 | rhettinger | set | messages:
+ msg375500 |
| 2020-08-16 01:40:56 | tim.peters | set | messages:
+ msg375498 |
| 2020-08-15 18:37:31 | rhettinger | set | messages:
+ msg375489 |
| 2020-08-15 17:44:58 | tim.peters | set | messages:
+ msg375483 |
| 2020-08-15 05:03:13 | tim.peters | set | messages:
+ msg375448 |
| 2020-08-15 04:54:40 | rhettinger | set | messages:
+ msg375447 |
| 2020-08-15 00:51:24 | rhettinger | set | messages:
+ msg375442 |
| 2020-08-14 23:29:18 | rhettinger | set | messages:
+ msg375440 |
| 2020-08-14 22:54:06 | rhettinger | set | messages:
+ msg375437 |
| 2020-08-11 07:50:30 | mark.dickinson | set | messages:
+ msg375166 |
| 2020-08-10 05:00:15 | rhettinger | set | messages:
+ msg375096 |
| 2020-08-10 04:55:56 | rhettinger | set | messages:
- msg375095 |
| 2020-08-10 04:54:54 | rhettinger | set | files:
+ test_hypot.py |
| 2020-08-10 04:54:42 | rhettinger | set | files:
- test_hypot.py |
| 2020-08-10 04:52:35 | rhettinger | set | files:
+ test_hypot.py
messages:
+ msg375095 |
| 2020-08-10 04:50:34 | rhettinger | set | files:
- test_hypot.py |
| 2020-08-10 01:29:50 | rhettinger | set | files:
+ test_hypot.py |
| 2020-08-10 01:19:50 | rhettinger | set | keywords:
+ patch
stage: patch review
pull_requests:
+ pull_request20937 |
| 2020-08-10 01:14:14 | rhettinger | create | |
{kind=link}