Issue41486
This issue tracker has been migrated to GitHub,
and is currently read-only.
For more information,
see the GitHub FAQs in the Python's Developer Guide.
Created on 2020-08-05 09:55 by malin, last changed 2022-04-11 14:59 by admin. This issue is now closed.
| Files | ||||
|---|---|---|---|---|
| File name | Uploaded | Description | Edit | |
| 0to2GB_step30MB.png | malin, 2020-08-05 09:58 | Decompress from 0 to 2GB, 30MB step | ||
| 0to200MB_step2MB.png | malin, 2020-08-05 09:58 | Decompress from 0 to 200MB, 2MB step | ||
| 0to20MB_step64KB.png | malin, 2020-08-05 09:59 | Decompress from 0 to 20MB, 64KB step | ||
| benchmark.py | malin, 2020-08-05 09:59 | benchmark special data (all data consists of b'a') | ||
| benchmark_real.py | malin, 2020-08-05 09:59 | benchmark real data | ||
| different_factors.png | malin, 2020-10-28 06:28 | |||
| 45d7526.diff | malin, 2021-04-27 10:09 | |||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pull Requests | |||
|---|---|---|---|
| URL | Status | Linked | Edit |
| PR 21740 | merged | malin, 2020-08-05 10:02 | |
| PR 25738 | merged | malin, 2021-04-30 02:53 | |
| PR 26143 | merged | malin, 2021-05-15 14:32 | |
| PR 27025 | merged | miss-islington, 2021-07-05 01:10 | |
| Messages (20) | |||
|---|---|---|---|
| msg374867 - (view) | Author: Ma Lin (malin) * | Date: 2020-08-05 09:55 | |
🔵 bz2/lzma module's current growth algorithm
bz2/lzma module's initial output buffer size is 8KB [1][2], and they are using this output buffer growth algorithm [3][4]:
newsize = size + (size >> 3) + 6
[1] https://github.com/python/cpython/blob/v3.9.0b4/Modules/_bz2module.c#L109
[2] https://github.com/python/cpython/blob/v3.9.0b4/Modules/_lzmamodule.c#L124
[3] https://github.com/python/cpython/blob/v3.9.0b4/Modules/_lzmamodule.c#L133
[4] https://github.com/python/cpython/blob/v3.9.0b4/Modules/_bz2module.c#L121
For many case, the output buffer is resized too many times.
You may paste this code to REPL to see the growth step:
size = 8*1024
for i in range(1, 120):
print('Step %d ' % i, format(size, ','), 'bytes')
size = size + (size >> 3) + 6
Step 1 8,192 bytes
Step 2 9,222 bytes
Step 3 10,380 bytes
Step 4 11,683 bytes
Step 5 13,149 bytes
Step 6 14,798 bytes
...
🔵 zlib module's current growth algorithm
zlib module's initial output buffer size is 16KB [5], in each growth the buffer size doubles [6].
[5] https://github.com/python/cpython/blob/v3.9.0b4/Modules/zlibmodule.c#L32
[6] https://github.com/python/cpython/blob/v3.9.0b4/Modules/zlibmodule.c#L174
This algorithm has a higher risk of running out of memory:
...
Step 14 256 MB
Step 15 512 MB
Step 16 1 GB
Step 17 2 GB
Step 18 4 GB
Step 19 8 GB
Step 20 16 GB
Step 21 32 GB
Step 22 64 GB
...
🔵 Add _BlocksOutputBuffer for bz2/lzma/zlib module
Proposed PR uses a list of bytes object to represent output buffer.
It can eliminate the overhead of resizing (bz2/lzma), and prevent excessive memory footprint (zlib).
I only tested decompression, because the result is more obvious than compression.
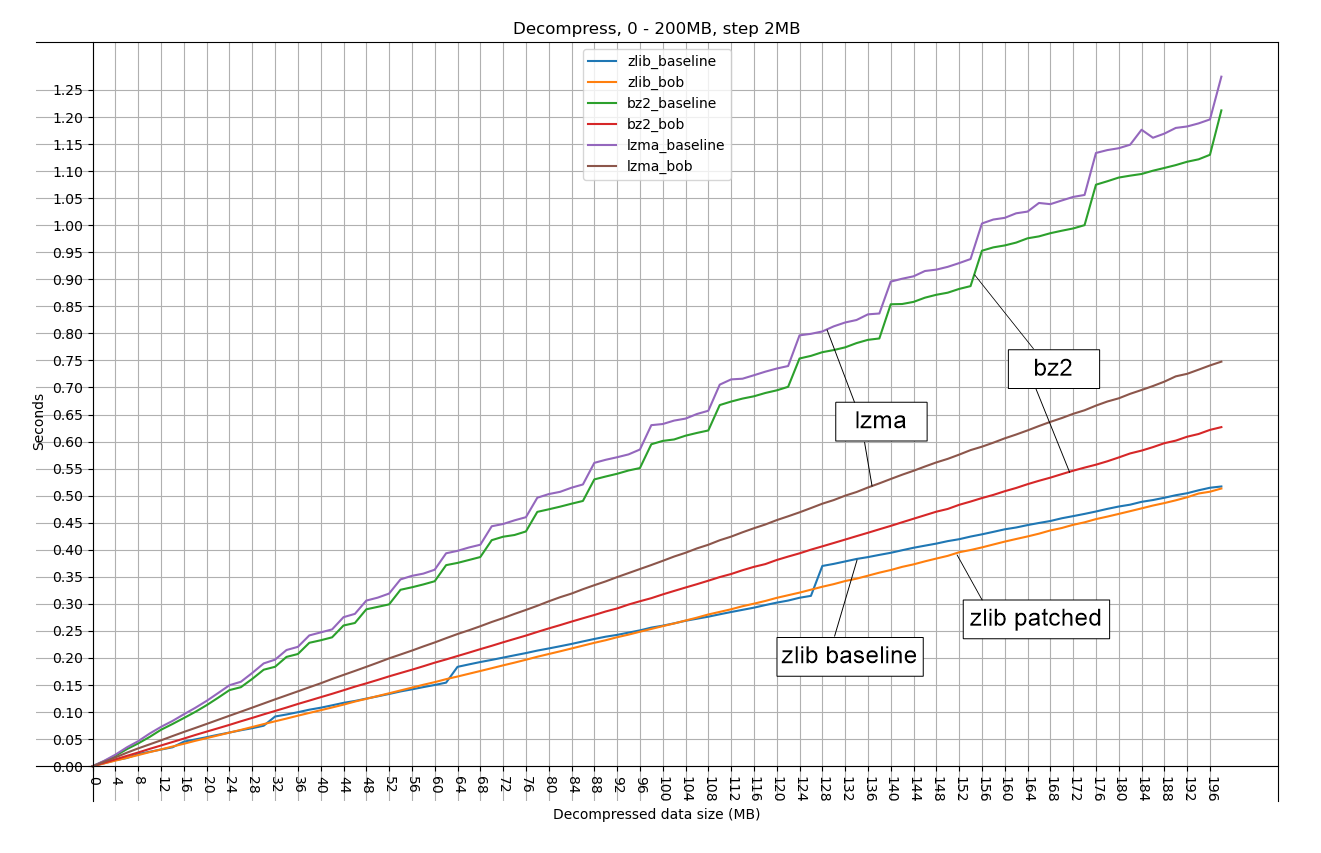
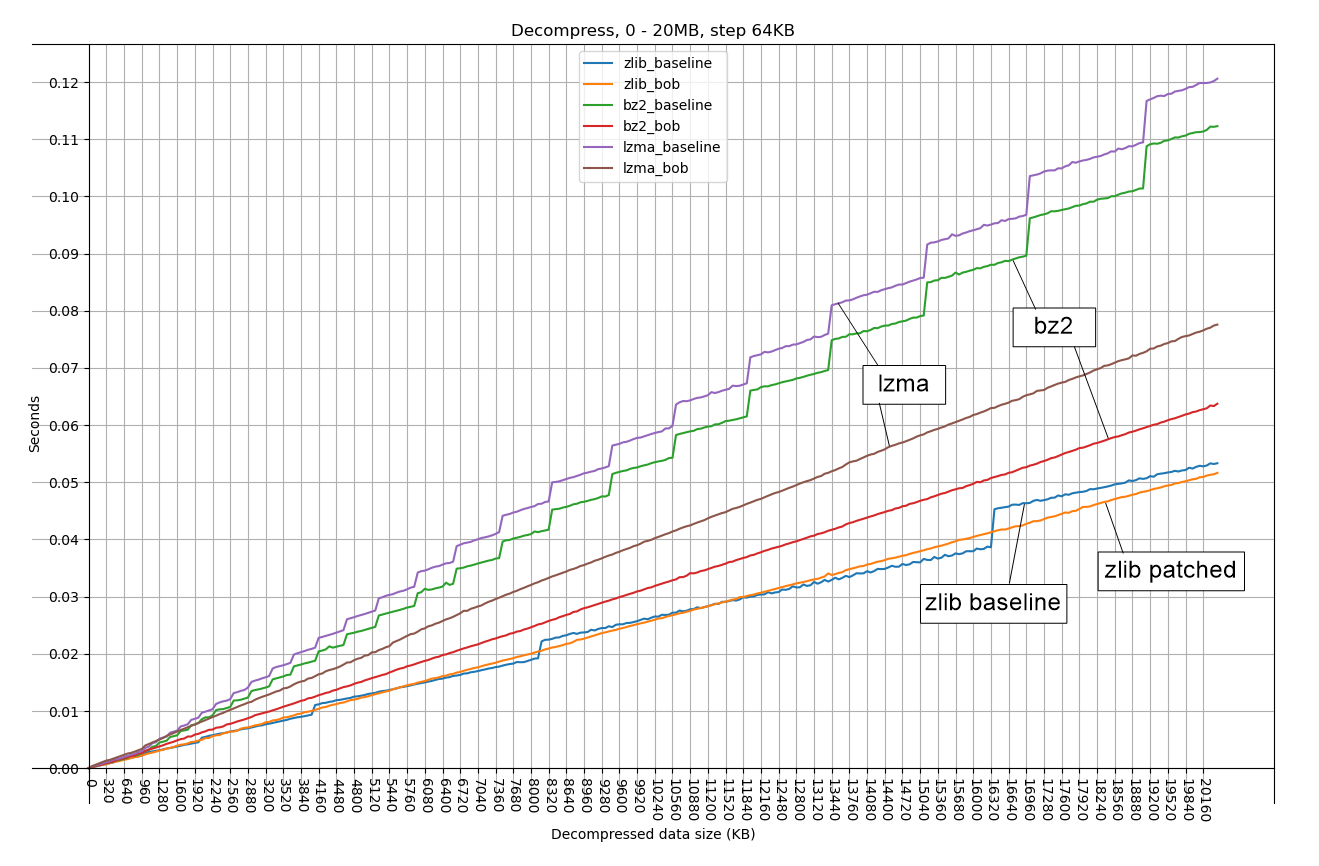
For special data benchmark (all data consists of b'a'), see these attached pictures, _BlocksOutputBuffer has linear performance:
(Benchmark by attached file benchmark.py)
0to2GB_step30MB.png (Decompress from 0 to 2GB, 30MB step)
0to200MB_step2MB.png (Decompress from 0 to 200MB, 2MB step)
0to20MB_step64KB.png (Decompress from 0 to 20MB, 64KB step)
After switching to _BlocksOutputBuffer, the code of bz2/lzma is more concise, the code of zlib is basically translated statement by statement, IMO it's safe and easy for review.
🔵 Real data benchmark
For real data, the weight of resizing output buffer is not big, so the performance improvement is not as big as above pictures:
(Benchmark by attached file benchmark_real.py)
----------------- bz2 -----------------
linux-2.6.39.4.tar.bz2
input size: 76,097,195, output size: 449,638,400
best of 5: [baseline_raw] 12.954 sec -> [patched_raw] 11.600 sec, 1.12x faster (-10%)
firefox-79.0.linux-i686.tar.bz2
input size: 74,109,706, output size: 228,055,040
best of 5: [baseline_raw] 8.511 sec -> [patched_raw] 7.829 sec, 1.09x faster (-8%)
ffmpeg-4.3.1.tar.bz2
input size: 11,301,038, output size: 74,567,680
best of 5: [baseline_raw] 1.915 sec -> [patched_raw] 1.671 sec, 1.15x faster (-13%)
gimp-2.10.20.tar.bz2
input size: 33,108,938, output size: 214,179,840
best of 5: [baseline_raw] 5.794 sec -> [patched_raw] 4.964 sec, 1.17x faster (-14%)
sde-external-8.56.0-2020-07-05-lin.tar.bz2
input size: 26,746,086, output size: 92,129,280
best of 5: [baseline_raw] 3.153 sec -> [patched_raw] 2.835 sec, 1.11x faster (-10%)
----------------- lzma -----------------
linux-5.7.10.tar.xz
input size: 112,722,840, output size: 966,062,080
best of 5: [baseline_raw] 9.813 sec -> [patched_raw] 7.434 sec, 1.32x faster (-24%)
linux-2.6.39.4.tar.xz
input size: 63,243,812, output size: 449,638,400
best of 5: [baseline_raw] 5.256 sec -> [patched_raw] 4.200 sec, 1.25x faster (-20%)
gcc-9.3.0.tar.xz
input size: 70,533,868, output size: 618,608,640
best of 5: [baseline_raw] 6.398 sec -> [patched_raw] 4.878 sec, 1.31x faster (-24%)
Python-3.8.5.tar.xz
input size: 18,019,640, output size: 87,531,520
best of 5: [baseline_raw] 1.315 sec -> [patched_raw] 1.098 sec, 1.20x faster (-16%)
firefox-79.0.source.tar.xz
input size: 333,220,776, output size: 2,240,573,440
best of 5: [baseline_raw] 25.339 sec -> [patched_raw] 19.661 sec, 1.29x faster (-22%)
----------------- zlib -----------------
linux-5.7.10.tar.gz
input size: 175,493,557, output size: 966,062,080
best of 5: [baseline_raw] 2.360 sec -> [patched_raw] 2.401 sec, 1.02x slower (+2%)
linux-2.6.39.4.tar.gz
input size: 96,011,459, output size: 449,638,400
best of 5: [baseline_raw] 1.215 sec -> [patched_raw] 1.216 sec, 1.00x slower (+0%)
gcc-9.3.0.tar.gz
input size: 124,140,228, output size: 618,608,640
best of 5: [baseline_raw] 1.668 sec -> [patched_raw] 1.555 sec, 1.07x faster (-7%)
Python-3.8.5.tgz
input size: 24,149,093, output size: 87,531,520
best of 5: [baseline_raw] 0.263 sec -> [patched_raw] 0.253 sec, 1.04x faster (-4%)
openjdk-14.0.2_linux-x64_bin.tar.gz
input size: 198,606,190, output size: 335,175,680
best of 5: [baseline_raw] 1.273 sec -> [patched_raw] 1.221 sec, 1.04x faster (-4%)
postgresql-10.12-1-linux-x64-binaries.tar.gz
input size: 159,090,037, output size: 408,678,400
best of 5: [baseline_raw] 1.415 sec -> [patched_raw] 1.401 sec, 1.01x faster (-1%)
-------------- benchmark end --------------
🔵 Add .readall() function to _compression.DecompressReader class
The last commit add .readall() function to _compression.DecompressReader, it optimize the .read(-1) for BZ2File/LZMAFile/GzipFile object.
The following description is a bit complicate:
1, BZ2File/LZMAFile/GzipFile object has a `self._buffer` attribute [7]:
raw = _compression.DecompressReader(fp, BZ2Decompressor/LZMADecompressor/zlib.decompressobj)
self._buffer = io.BufferedReader(raw)
[7] https://github.com/python/cpython/blob/v3.9.0b4/Lib/lzma.py#L130-L132
2, When call `.read(-1)` function (read all data) on BZ2File/LZMAFile/GzipFile
object, will dispatch to `self._buffer`'s .read(-1) function [8].
[8] https://github.com/python/cpython/blob/v3.9.0b4/Lib/lzma.py#L200
3, `self._buffer` is an io.BufferedReader object, it will dispatch to underlying
stream's readall() function [9].
[9] https://github.com/python/cpython/blob/v3.9.0b4/Modules/_io/bufferedio.c#L1538-L1542
4, The underlying stream is a _compression.DecompressReader object, which is a
subclass of io.RawIOBase [10].
[10] https://github.com/python/cpython/blob/v3.9.0b4/Lib/_compression.py#L33
5, Then io.RawIOBase's readall() function is called, but it's very inefficient.
It only read DEFAULT_BUFFER_SIZE (8KB) data each time. [11]
[11] https://github.com/python/cpython/blob/v3.9.0b4/Modules/_io/iobase.c#L968-L969
6, So each time the decompressor will try to decompress 8KB input data to a 8KB
output buffer [12]:
data = self._decompressor.decompress(8KB_input_buffer, 8KB_output_buffer)
[12] https://github.com/python/cpython/blob/v3.9.0b4/Lib/_compression.py#L103
In most cases, the input buffer will not be fully decompressed, this brings
unnecessary overhead.
After adding the .readall() function to _compression.DecompressReader, the
limit of the output buffer size has been removed.
This change requires _BlocksOutputBuffer, otherwise, in extreme cases (small
input buffer be decompressed to 100MB data), it will be slower due to the
overhead of buffer resizing.
Benchmark with real data, call .read(-1) on XXXXFile object:
(Benchmark by attached file benchmark_real.py)
----------------- BZ2File -----------------
linux-2.6.39.4.tar.bz2
input size: 76,097,195, output size: 449,638,400
best of 5: [baseline_file] 12.371 sec -> [patched_file] 12.035 sec, 1.03x faster (-3%)
firefox-79.0.linux-i686.tar.bz2
input size: 74,109,706, output size: 228,055,040
best of 5: [baseline_file] 8.233 sec -> [patched_file] 8.124 sec, 1.01x faster (-1%)
ffmpeg-4.3.1.tar.bz2
input size: 11,301,038, output size: 74,567,680
best of 5: [baseline_file] 1.747 sec -> [patched_file] 1.724 sec, 1.01x faster (-1%)
gimp-2.10.20.tar.bz2
input size: 33,108,938, output size: 214,179,840
best of 5: [baseline_file] 5.220 sec -> [patched_file] 5.162 sec, 1.01x faster (-1%)
sde-external-8.56.0-2020-07-05-lin.tar.bz2
input size: 26,746,086, output size: 92,129,280
best of 5: [baseline_file] 2.935 sec -> [patched_file] 2.899 sec, 1.01x faster (-1%)
----------------- LZMAFile -----------------
linux-5.7.10.tar.xz
input size: 112,722,840, output size: 966,062,080
best of 5: [baseline_file] 7.712 sec -> [patched_file] 7.670 sec, 1.01x faster (-1%)
linux-2.6.39.4.tar.xz
input size: 63,243,812, output size: 449,638,400
best of 5: [baseline_file] 4.342 sec -> [patched_file] 4.274 sec, 1.02x faster (-2%)
gcc-9.3.0.tar.xz
input size: 70,533,868, output size: 618,608,640
best of 5: [baseline_file] 5.077 sec -> [patched_file] 4.974 sec, 1.02x faster (-2%)
Python-3.8.5.tar.xz
input size: 18,019,640, output size: 87,531,520
best of 5: [baseline_file] 1.093 sec -> [patched_file] 1.087 sec, 1.01x faster (-1%)
firefox-79.0.source.tar.xz
input size: 333,220,776, output size: 2,240,573,440
best of 5: [baseline_file] 20.748 sec -> [patched_file] 20.276 sec, 1.02x faster (-2%)
----------------- GzipFile -----------------
linux-5.7.10.tar.gz
input size: 175,493,567, output size: 966,062,080
best of 5: [baseline_file] 4.422 sec -> [patched_file] 3.803 sec, 1.16x faster (-14%)
linux-2.6.39.4.tar.gz
input size: 96,011,469, output size: 449,638,400
best of 5: [baseline_file] 2.119 sec -> [patched_file] 1.863 sec, 1.14x faster (-12%)
gcc-9.3.0.tar.gz
input size: 124,140,238, output size: 618,608,640
best of 5: [baseline_file] 2.825 sec -> [patched_file] 2.409 sec, 1.17x faster (-15%)
Python-3.8.5.tgz
input size: 24,149,103, output size: 87,531,520
best of 5: [baseline_file] 0.410 sec -> [patched_file] 0.349 sec, 1.18x faster (-15%)
openjdk-14.0.2_linux-x64_bin.tar.gz
input size: 198,606,200, output size: 335,175,680
best of 5: [baseline_file] 1.885 sec -> [patched_file] 1.702 sec, 1.11x faster (-10%)
postgresql-10.12-1-linux-x64-binaries.tar.gz
input size: 159,090,047, output size: 408,678,400
best of 5: [baseline_file] 2.236 sec -> [patched_file] 2.002 sec, 1.12x faster (-10%)
-------------- benchmark end --------------
|
|||
| msg379682 - (view) | Author: STINNER Victor (vstinner) *  |
Date: 2020-10-26 19:11 | |
Ma Lin proposed this approach (PR 21740) for _PyBytesWriter/_PyUnicodeWriter on python-dev: https://mail.python.org/archives/list/python-dev@python.org/message/UMB52BEZCX424K5K2ZNPWV7ZTQAGYL53/ |
|||
| msg379683 - (view) | Author: STINNER Victor (vstinner) * |
Date: 2020-10-26 19:45 | |
It would be interested to see if using _PyBytesWriter in bz2, lzma, zlib and _io.FileIO.readall() would speed up the code. I would prefer to centralize the buffer allocation logic in _PyBytesWriter rather than having custom code in each file. _PyBytesWriter is designed to reduce the number of realloc() by using overallocation, it uses a different overallocation ratio on Windows, and it uses a small buffer allocated on the stack for strings up to 512 bytes. |
|||
| msg379817 - (view) | Author: Ma Lin (malin) * | Date: 2020-10-28 06:28 | |
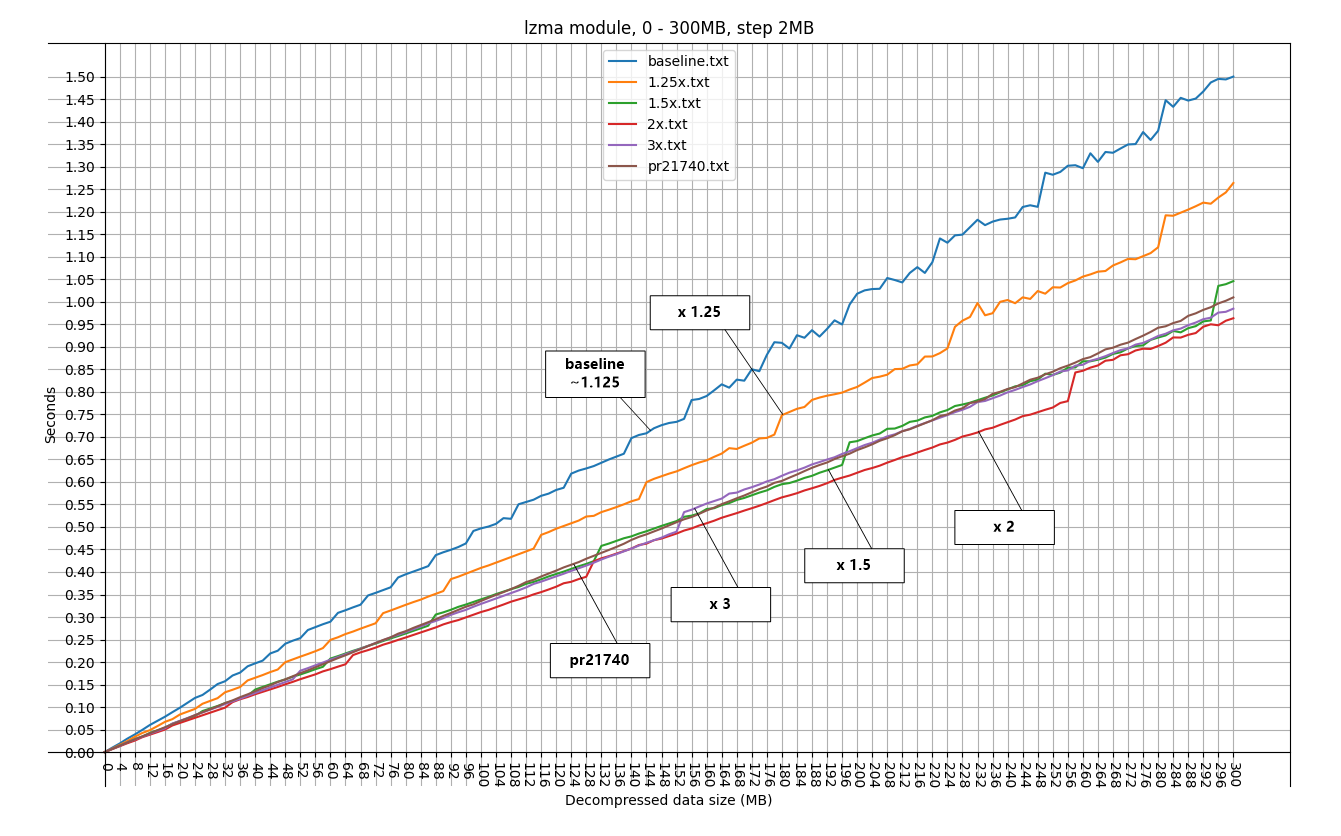
I modify lzma module to use different growth factors, see attached picture different_factors.png
1.5x should be the growth factor of _PyBytesWriter under Windows.
So if change _PyBytesWriter to use memory blocks, maybe there will be no performance improvement.
Over allocate factor of _PyBytesWriter:
# ifdef MS_WINDOWS
# define OVERALLOCATE_FACTOR 2
# else
# define OVERALLOCATE_FACTOR 4
# endif
(I'm using Windows 10)
|
|||
| msg390269 - (view) | Author: Ma Lin (malin) * | Date: 2021-04-06 01:51 | |
ping |
|||
| msg390793 - (view) | Author: Gregory P. Smith (gregory.p.smith) * |
Date: 2021-04-11 19:57 | |
I left some review comments on the PR. I like the algorithm being used. I don't really _like_ that this is a .h file acting as a C template to inject effectively the same static code into each module that wants to use it... Which I think is the concern Victor is expressing in a comment above. I could live with this PR as is because it is at least easy to maintain. But I anticipate we'll want to refactor it in the future to be shared code instead of a copy compiled per module. This is the kind of thing that also makes sense to be usable outside of just these modules. Compression modules for the other popular compression algorithms currently not in the stdlib but available on PyPI shouldn't need to reinvent this wheel on their own without reason. (lzo, brotli, zstandard, no doubt others...) It is also worth looking at those to see if they've already implemented something like this and how it differs. |
|||
| msg390794 - (view) | Author: Gregory P. Smith (gregory.p.smith) * |
Date: 2021-04-11 20:03 | |
looking around it appears you've proposed an independent implementation of this for the thir party brotli module? https://github.com/google/brotli/pull/856 that is what i mean about making this reusable :) |
|||
| msg390812 - (view) | Author: Ma Lin (malin) * | Date: 2021-04-12 02:26 | |
> I don't really _like_ that this is a .h file acting as a C template to inject > effectively the same static code into each module that wants to use it... > Which I think is the concern Victor is expressing in a comment above. I think so too. The defines of BOB_BUFFER_TYPE/BOB_SIZE_TYPE/BOB_SIZE_MAX are ugly. If put the core code together, these defines can be put in a thin wrapper in _bz2module.c/_lzmamodule.c/zlibmodule.c files. This can be done now, but it's ideal to improve it more thoroughly in 3.11. _PyBytesWriter has different behavior, user may access existing data as plain data, which is impossible for _BlocksOutputBuffer. An API/code can be carefully designed, efficient/flexible/elegant, then the code may be used in some sites in CPython. |
|||
| msg391840 - (view) | Author: Ma Lin (malin) * | Date: 2021-04-25 06:06 | |
> The defines of BOB_BUFFER_TYPE/BOB_SIZE_TYPE/BOB_SIZE_MAX are ugly. If put the core code together, these defines can be put in a thin wrapper in _bz2module.c/_lzmamodule.c/zlibmodule.c files. I tried, it looks well. I will updated the PR within one or two days. The code is more concise, and the burden of review is not big. |
|||
| msg391904 - (view) | Author: Ma Lin (malin) * | Date: 2021-04-26 11:54 | |
Very sorry for update at the last moment. But after the update, we should no need to touch it in the future, so I think it's worthy. Please review the last commit in PR 21740, the previous commits have not been changed. IMO if use a Git client such as TortoiseGit, reviewing may be more convenient. The changes: 1, Move `Modules/blocks_output_buffer.h` to `Include/internal/pycore_blocks_output_buffer.h` Keep the `Modules` folder clean. 2, Ask the user to initialize the struct instance like this, and use assertions to check it: _BlocksOutputBuffer buffer = {.list = NULL}; Then no longer worry about whether buffer.list is uninitialized in error handling. There is an extra assignment, but it's beneficial to long-term code maintenance. 3, Change the type of BUFFER_BLOCK_SIZE from `int` to `Py_ssize_t`. The core code can remove a few type casts. 4, These functions return allocated size on success, return -1 on failure: _BlocksOutputBuffer_Init() _BlocksOutputBuffer_InitAndGrow() _BlocksOutputBuffer_InitWithSize() _BlocksOutputBuffer_Grow() If the code is used in other sites, this API is simpler. 5, All functions are decorated with `inline`. If the compiler is smart enough, it's possible to eliminate some code when `max_length` is constant and < 0. |
|||
| msg392052 - (view) | Author: Ma Lin (malin) * | Date: 2021-04-27 10:09 | |
The above changes were made in this commit:
split core code and wrappers
55705f6dc28ff4dc6183e0eb57312c885d19090a
After that commit, there is a new commit, it resolves the code conflicts introduced by PR 22126 one hour ago.
Merge branch 'master' into blocks_output_buffer
45d752649925765b1b3cf39e9045270e92082164
Sorry to complicate the review again.
I should ask Łukasz Langa to merge PR 22126 after this issue is resolved, since resolving code conflicts in PR 22126 is easier.
For the change from 55705f6 to 45d7526, see the uploaded file (45d7526.diff), it can also be easily seen with a Git client.
|
|||
| msg392166 - (view) | Author: Gregory P. Smith (gregory.p.smith) * |
Date: 2021-04-28 06:59 | |
New changeset f9bedb630e8a0b7d94e1c7e609b20dfaa2b22231 by Ma Lin in branch 'master': bpo-41486: Faster bz2/lzma/zlib via new output buffering (GH-21740) https://github.com/python/cpython/commit/f9bedb630e8a0b7d94e1c7e609b20dfaa2b22231 |
|||
| msg392167 - (view) | Author: Gregory P. Smith (gregory.p.smith) * |
Date: 2021-04-28 07:03 | |
Thanks, this is great work! Especially when living within the constraints of C and the existing code. |
|||
| msg392168 - (view) | Author: Ma Lin (malin) * | Date: 2021-04-28 07:12 | |
Thanks for reviewing this big patch. Your review makes the code better. |
|||
| msg392372 - (view) | Author: Ma Lin (malin) * | Date: 2021-04-30 02:55 | |
Found a backward incompatible behavior. Before the patch, in 64-bit build, zlib module allows the initial size > UINT32_MAX. It creates a bytes object, and uses a sliding window to deal with the UINT32_MAX limit: https://github.com/python/cpython/blob/v3.9.4/Modules/zlibmodule.c#L183 After the patch, when init_size > UINT32_MAX, it raises a ValueError. PR 25738 fixes this backward incompatibility. If the initial size > UINT32_MAX, it clamps to UINT32_MAX, rather than raising an exception. Moreover, if you don't mind, I would like to take this opportunity to rename the wrapper functions from Buffer_* to OutputBuffer_*, so that the readers can easily distinguish between input buffer and output buffer. If you don't think it's necessary, you may merge PR 25738 as is. |
|||
| msg392384 - (view) | Author: Gregory P. Smith (gregory.p.smith) * |
Date: 2021-04-30 06:16 | |
Renaming to OutputBuffer sounds like a good idea. On Thu, Apr 29, 2021, 7:55 PM Ma Lin <report@bugs.python.org> wrote: > > Ma Lin <malincns@163.com> added the comment: > > Found a backward incompatible behavior. > > Before the patch, in 64-bit build, zlib module allows the initial size > > UINT32_MAX. > It creates a bytes object, and uses a sliding window to deal with the > UINT32_MAX limit: > https://github.com/python/cpython/blob/v3.9.4/Modules/zlibmodule.c#L183 > > After the patch, when init_size > UINT32_MAX, it raises a ValueError. > > PR 25738 fixes this backward incompatibility. > If the initial size > UINT32_MAX, it clamps to UINT32_MAX, rather than > raising an exception. > > Moreover, if you don't mind, I would like to take this opportunity to > rename the wrapper functions from Buffer_* to OutputBuffer_*, so that the > readers can easily distinguish between input buffer and output buffer. > If you don't think it's necessary, you may merge PR 25738 as is. > > ---------- > > _______________________________________ > Python tracker <report@bugs.python.org> > <https://bugs.python.org/issue41486> > _______________________________________ > |
|||
| msg392544 - (view) | Author: Gregory P. Smith (gregory.p.smith) * |
Date: 2021-04-30 23:33 | |
New changeset 251ffa9d2b16b091046720628deb6a7906c35d29 by Ma Lin in branch 'master': bpo-41486: Fix initial buffer size can't > UINT32_MAX in zlib module (GH-25738) https://github.com/python/cpython/commit/251ffa9d2b16b091046720628deb6a7906c35d29 |
|||
| msg393715 - (view) | Author: Ma Lin (malin) * | Date: 2021-05-15 14:33 | |
Sorry, for the (init_size > UINT32_MAX) problem, I have a better solution.
Please imagine this scenario:
- before the patch
- in 64-bit build
- use zlib.decompress() function
- the exact decompressed size is known and > UINT32_MAX (e.g. 10 GiB)
If set the `bufsize` argument to the decompressed size, it used to have a fast path:
zlib.decompress(data, bufsize=10*1024*1024*1024)
Fast path when (the initial size == the actual size):
https://github.com/python/cpython/blob/v3.9.5/Modules/zlibmodule.c#L424-L426
https://github.com/python/cpython/blob/v3.9.5/Objects/bytesobject.c#L3008-L3011
But in the current code, the initial size is clamped to UINT32_MAX, so there are two regressions:
1. allocate double RAM. (~20 GiB, blocks and the final bytes)
2. need to memcpy from blocks to the final bytes.
PR 26143 uses an UINT32_MAX sliding window for the first block, now the initial buffer size can be greater than UINT32_MAX.
_BlocksOutputBuffer_Finish() already has a fast path for single block. Benchmark this code:
zlib.decompress(data, bufsize=10*1024*1024*1024)
time RAM
before: 7.92 sec, ~20 GiB
after: 6.61 sec, 10 GiB
(AMD 3600X, DDR4-3200, decompressed data is 10_GiB * b'a')
Maybe some user code rely on this corner case.
This should be the last revision, then there is no regression in any case.
|
|||
| msg396964 - (view) | Author: Gregory P. Smith (gregory.p.smith) * |
Date: 2021-07-05 01:10 | |
New changeset a9a69bb3ea1e6cf54513717212aaeae0d61b24ee by Ma Lin in branch 'main': bpo-41486: zlib uses an UINT32_MAX sliding window for the output buffer (GH-26143) https://github.com/python/cpython/commit/a9a69bb3ea1e6cf54513717212aaeae0d61b24ee |
|||
| msg396965 - (view) | Author: miss-islington (miss-islington) | Date: 2021-07-05 01:33 | |
New changeset 22bcc0768e0f7eda2ae4de63aef113b1ddb4ddef by Miss Islington (bot) in branch '3.10': bpo-41486: zlib uses an UINT32_MAX sliding window for the output buffer (GH-26143) https://github.com/python/cpython/commit/22bcc0768e0f7eda2ae4de63aef113b1ddb4ddef |
|||
| History | |||
|---|---|---|---|
| Date | User | Action | Args |
| 2022-04-11 14:59:34 | admin | set | github: 85658 |
| 2021-07-05 01:33:03 | miss-islington | set | messages: + msg396965 |
| 2021-07-05 01:10:55 | miss-islington | set | nosy:
+ miss-islington pull_requests: + pull_request25585 |
| 2021-07-05 01:10:51 | gregory.p.smith | set | messages: + msg396964 |
| 2021-05-15 14:33:59 | malin | set | messages: + msg393715 |
| 2021-05-15 14:32:50 | malin | set | pull_requests: + pull_request24779 |
| 2021-04-30 23:33:00 | gregory.p.smith | set | messages: + msg392544 |
| 2021-04-30 06:16:52 | gregory.p.smith | set | messages: + msg392384 |
| 2021-04-30 02:55:42 | malin | set | messages: + msg392372 |
| 2021-04-30 02:53:13 | malin | set | pull_requests: + pull_request24429 |
| 2021-04-28 07:12:10 | malin | set | messages: + msg392168 |
| 2021-04-28 07:03:16 | gregory.p.smith | set | status: open -> closed resolution: fixed messages: + msg392167 stage: patch review -> resolved |
| 2021-04-28 06:59:01 | gregory.p.smith | set | messages: + msg392166 |
| 2021-04-27 10:09:39 | malin | set | files:
+ 45d7526.diff messages: + msg392052 |
| 2021-04-26 11:54:31 | malin | set | messages: + msg391904 |
| 2021-04-25 06:06:31 | malin | set | messages: + msg391840 |
| 2021-04-12 02:26:19 | malin | set | messages: + msg390812 |
| 2021-04-11 20:03:38 | gregory.p.smith | set | messages: + msg390794 |
| 2021-04-11 19:57:56 | gregory.p.smith | set | messages: + msg390793 |
| 2021-04-09 12:01:20 | vstinner | set | nosy:
- vstinner |
| 2021-04-09 07:09:19 | xtreak | set | nosy:
+ methane |
| 2021-04-06 07:46:44 | gregory.p.smith | set | nosy:
+ gregory.p.smith |
| 2021-04-06 01:51:24 | malin | set | messages: + msg390269 |
| 2020-10-28 06:28:16 | malin | set | files:
+ different_factors.png messages: + msg379817 |
| 2020-10-26 19:45:11 | vstinner | set | messages: + msg379683 |
| 2020-10-26 19:11:27 | vstinner | set | nosy:
+ vstinner messages: + msg379682 |
| 2020-08-05 10:02:14 | malin | set | keywords:
+ patch stage: patch review pull_requests: + pull_request20886 |
| 2020-08-05 09:59:54 | malin | set | files: + benchmark_real.py |
| 2020-08-05 09:59:34 | malin | set | files: + benchmark.py |
| 2020-08-05 09:59:05 | malin | set | files: + 0to20MB_step64KB.png |
| 2020-08-05 09:58:49 | malin | set | files: + 0to200MB_step2MB.png |
| 2020-08-05 09:58:27 | malin | set | files: + 0to2GB_step30MB.png |
| 2020-08-05 09:55:44 | malin | create | |