Issue38582
This issue tracker has been migrated to GitHub,
and is currently read-only.
For more information,
see the GitHub FAQs in the Python's Developer Guide.
Created on 2019-10-24 12:01 by veaba, last changed 2022-04-11 14:59 by admin.
| Files | ||||
|---|---|---|---|---|
| File name | Uploaded | Description | Edit | |
| QQ图片20191024195805.png | veaba, 2019-10-24 12:00 | |||
{kind=link}
| Repositories containing patches | |||
|---|---|---|---|
| https://github.com/veaba/learn-python/blob/master/write_error.py | |||
| https://github.com/veaba/tensorflow-docs/blob/master/scripts/spider_tensorflow_docs.py#L39-L56 | |||
| Messages (16) | |||
|---|---|---|---|
| msg355328 - (view) | Author: veaba (veaba) | Date: 2019-10-24 12:00 | |
Regular match overflow
code:
```python
import re
# list => str
def list_to_str(str_list, code=""):
if isinstance(str_list, list):
return code.join(str_list)
else:
return ''
def fn_parse_code(list_str, text):
code_text_str=''
code_text_str = list_to_str(list_str, '|') # => xxx|oo
reg_list = ['+', '.', '[', ']','((','))']
for reg in reg_list:
code_text_str_temp = code_text_str.replace(reg, "\\" + reg).replace('((','(\\(').replace('))','))')
code_text_str=code_text_str_temp
# compile
pattern_str = re.compile(code_text_str )
#list_str=>\\1\\2\\...
flag_str = ''
for item in enumerate(list_str):
flag_str = flag_str + "\\" + str(item[0] + 1)
print("1:",pattern_str)
print("2:",flag_str)
print("3:",text)
reg_text = re.sub(r''+code_text_str+'', "`" + flag_str + "`", text)
return reg_text
# a list
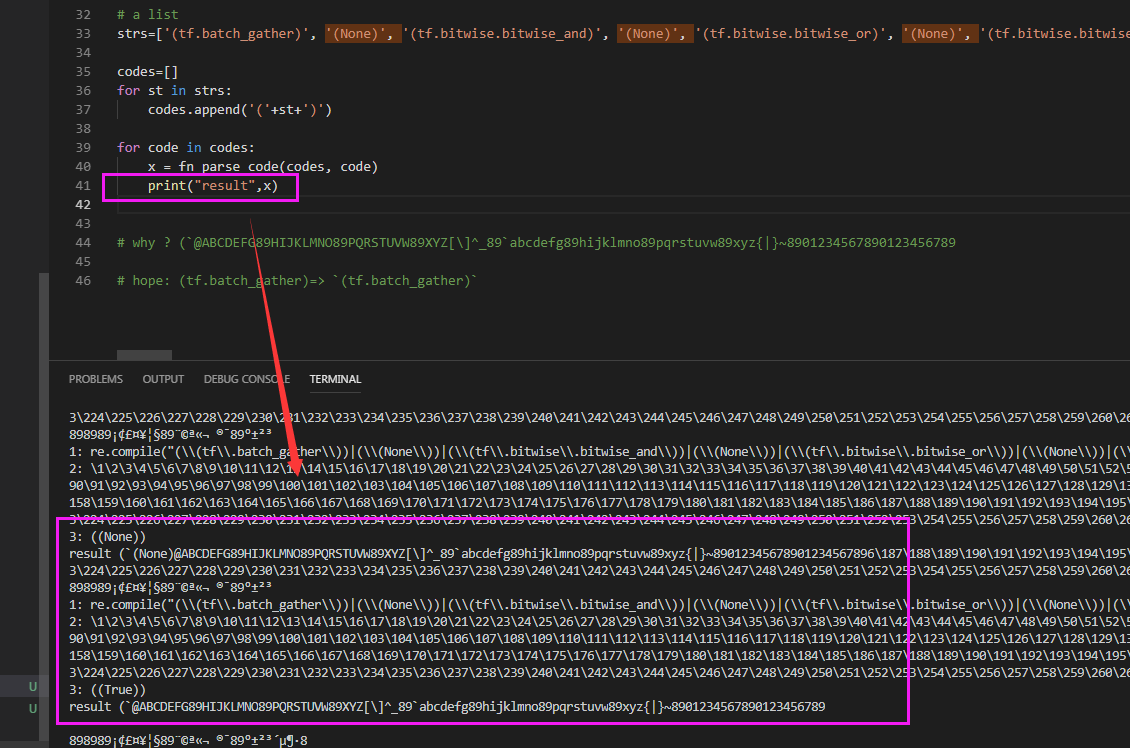
strs=['(tf.batch_gather)', '(None)', '(tf.bitwise.bitwise_and)', '(None)', '(tf.bitwise.bitwise_or)', '(None)', '(tf.bitwise.bitwise_xor)', '(None)', '(tf.bitwise.invert)', '(None)', '(tf.bitwise.left_shift)', '(None)', '(tf.bitwise.right_shift)', '(None)', '(tf.clip_by_value)', '(None)', '(tf.concat)', "('concat')", '(tf.debugging.check_numerics)', '(None)', '(tf.dtypes.cast)', '(None)', '(tf.dtypes.complex)', '(None)', '(tf.dtypes.saturate_cast)', '(None)', '(tf.dynamic_partition)', '(None)', '(tf.expand_dims)', '(None)', '(None)', '(None)', '(tf.gather_nd)', '(None)', '(0)', '(tf.gather)', '(None)', '(None)', '(None)', '(0)', '(tf.identity)', '(None)', '(tf.io.decode_base64)', '(None)', '(tf.io.decode_compressed)', "('')", '(None)', '(tf.io.encode_base64)', '(False)', '(None)', '(tf.math.abs)', '(None)', '(tf.math.acos)', '(None)', '(tf.math.acosh)', '(None)', '(tf.math.add_n)', '(None)', '(tf.math.add)', '(None)', '(tf.math.angle)', '(None)', '(tf.math.asin)', '(None)', '(tf.math.asinh)', '(None)', '(tf.math.atan2)', '(None)', '(tf.math.atan)', '(None)', '(tf.math.atanh)', '(None)', '(tf.math.ceil)', '(None)', '(tf.math.conj)', '(None)', '(tf.math.cos)', '(None)', '(tf.math.cosh)', '(None)', '(tf.math.digamma)', '(None)', '(tf.math.divide_no_nan)', '(None)', '(tf.math.divide)', '(None)', '(tf.math.equal)', '(None)', '(tf.math.erf)', '(None)', '(tf.math.erfc)', '(None)', '(tf.math.exp)', '(None)', '(tf.math.expm1)', '(None)', '(tf.math.floor)', '(None)', '(tf.math.floordiv)', '(None)', '(tf.math.floormod)', '(None)', '(tf.math.greater_equal)', '(None)', '(tf.math.greater)', '(None)', '(tf.math.imag)', '(None)', '(tf.math.is_finite)', '(None)', '(tf.math.is_inf)', '(None)', '(tf.math.is_nan)', '(None)', '(tf.math.less_equal)', '(None)', '(tf.math.less)', '(None)', '(tf.math.lgamma)', '(None)', '(tf.math.log1p)', '(None)', '(tf.math.log_sigmoid)', '(None)', '(tf.math.log)', '(None)', '(tf.math.logical_and)', '(None)', '(tf.math.logical_not)', '(None)', '(tf.math.logical_or)', '(None)', '(tf.math.logical_xor)', "('LogicalXor')", '(tf.math.maximum)', '(None)', '(tf.math.minimum)', '(None)', '(tf.math.multiply)', '(None)', '(tf.math.negative)', '(None)', '(tf.math.not_equal)', '(None)', '(tf.math.pow)', '(None)', '(tf.math.real)', '(None)', '(tf.math.reciprocal)', '(None)', '(tf.math.reduce_any)', '(None)', '(False)', '(None)', '(tf.math.reduce_max)', '(None)', '(False)', '(None)', '(tf.math.reduce_mean)', '(None)', '(False)', '(None)', '(tf.math.reduce_min)', '(None)', '(False)', '(None)', '(tf.math.reduce_prod)', '(None)', '(False)', '(None)', '(tf.math.reduce_sum)', '(None)', '(False)', '(None)', '(tf.math.rint)', '(None)', '(tf.math.round)', '(None)', '(tf.math.rsqrt)', '(None)', '(tf.math.sign)', '(None)', '(tf.math.sin)', '(None)', '(tf.math.sinh)', '(None)', '(tf.math.sqrt)', '(None)', '(tf.math.square)', '(None)', '(tf.math.squared_difference)', '(None)', '(tf.math.subtract)', '(None)', '(tf.math.tan)', '(None)', '(tf.math.truediv)', '(None)', '(tf.math.unsorted_segment_max)', '(None)', '(tf.math.unsorted_segment_mean)', '(None)', '(tf.math.unsorted_segment_min)', '(None)', '(tf.math.unsorted_segment_prod)', '(None)', '(tf.math.unsorted_segment_sqrt_n)', '(None)', '(tf.math.unsorted_segment_sum)', '(None)', '(tf.ones_like)', '(None)', '(None)', '(True)', '(tf.rank)', '(None)', '(tf.realdiv)', '(None)', '(tf.reduce_all)', '(None)', '(False)', '(None)', '(tf.size)', '(None)', '(tf.int32)', '(tf.squeeze)', '(None)', '(None)', '(None)', '(tf.stack)', '(0)', "('stack')", '(tf.strings.as_string)', '(-1)', '(False)', '(False)', '(-1)', "('')", '(None)', '(tf.strings.join)', "('')", '(None)', '(tf.strings.length)', '(None)', "('BYTE')", '(tf.strings.reduce_join)', '(None)', '(False)', "('')", '(None)', '(tf.strings.regex_full_match)', '(None)', '(tf.strings.regex_replace)', '(True)', '(None)', '(tf.strings.strip)', '(None)', '(tf.strings.substr)', '(None)', "('BYTE')", '(tf.strings.to_hash_bucket_fast)', '(None)', '(tf.strings.to_hash_bucket_strong)', '(None)', '(tf.strings.to_hash_bucket)', '(None)', '(tf.strings.to_hash_bucket)', '(None)', '(tf.strings.to_number)', '(tf.float32)', '(None)', '(tf.strings.unicode_script)', '(None)', '(tf.tile)', '(None)', '(tf.truncatediv)', '(None)', '(tf.truncatemod)', '(None)', '(tf.where)', '(None)', '(None)', '(None)', '(tf.zeros_like)', '(None)', '(None)', '(True)']
codes=[]
for st in strs:
codes.append('('+st+')')
for code in codes:
x = fn_parse_code(codes, code)
print("result",x)
# why ? (`@ABCDEFG89HIJKLMNO89PQRSTUVW89XYZ[\]^_89`abcdefg89hijklmno89pqrstuvw89xyz{|}~8901234567890123456789
# hope: (tf.batch_gather)=> `(tf.batch_gather)`
```
|
|||
| msg355330 - (view) | Author: Ma Lin (malin) * | Date: 2019-10-24 13:32 | |
An simpler reproduce code:
```
import re
NUM = 99
# items = [ '(001)', '(002)', '(003)', ..., '(NUM)']
items = [r'(%03d)' % i for i in range(1, 1+NUM)]
pattern = '|'.join(items)
# repl = '\1\2\3...\NUM'
temp = ('\\' + str(i) for i in range(1, 1+NUM))
repl = ''.join(temp)
text = re.sub(pattern, repl, '(001)')
print(text)
# if NUM == 99
# output: (001)
# if NUM == 100
# output: (001@)
# if NUM == 101
# output: (001@A)
```
|
|||
| msg355332 - (view) | Author: Ma Lin (malin) * | Date: 2019-10-24 14:19 | |
Backreference number in replace string can't >= 100 https://github.com/python/cpython/blob/v3.8.0/Lib/sre_parse.py#L1022-L1036 If none take this, I will try to fix this issue tomorrow. |
|||
| msg355343 - (view) | Author: Matthew Barnett (mrabarnett) *  |
Date: 2019-10-24 17:15 | |
A numeric escape of 3 digits is an octal (base 8) escape; the octal escape "\100" gives the same character as the hexadecimal escape "\x40". In a replacement template, you can use "\g<100>" if you want group 100 because \g<...> accepts both numeric and named group references. However, \g<...> is not accepted in a pattern. (By the way, in the "regex" module I added support for it in a pattern too.) |
|||
| msg355346 - (view) | Author: Vedran Čačić (veky) * | Date: 2019-10-24 18:32 | |
Is this actually needed? I can't remember ever needing more than 4 (in a pattern). I find it very hard to believe someone might actually have such a regex with more than a hundred backreferences. Probably it's just a misguided attempt to parse a nested structure with a regex. |
|||
| msg355350 - (view) | Author: veaba (veaba) | Date: 2019-10-25 01:59 | |
这里来自实际我的一个项目(https://github.com/veaba/tensorflow-docs/blob/master/scripts/spider_tensorflow_docs.py#L39-L56),当然也许我这个方法不是正确的,它只是我刚学python的一个尝试。 这个项目步骤是这样:根据HTML tag 提取文本转为markdown格式。<code> 标签,需要用符号“`”包围,然后循环里面将匹配的字符通过\\* 替换出来。 所以,你们见到了,我发现这样的一个正则溢出错误。 如果能够放开反斜杠替换符无限个数限制对我会很友好,当然如果真的不需要的话,我自己想别的办法。 ———————————————————————————————————— This is from a project I actually worked on (https://github.com/veaba/tensorflow-docs/blob/master/scripts/spider_tensorflow_docs.py#L39-L56). Of course, this method is not correct. It's just an attempt to learn python. The project steps are as follows: extract the text according to HTML tag and change it to markdown format. The < code > label needs to be surrounded by the symbol "`", and then the matching characters are replaced by \ \ * in the loop. So, as you can see, I found such a regular overflow error. It would be nice for me to be able to let go of the infinite number of backslash substitutions. Of course, if I really don't need it, I'll try something else. |
|||
| msg355352 - (view) | Author: Ma Lin (malin) * | Date: 2019-10-25 05:19 | |
@veaba Post only in English is fine. > Is this actually needed? Maybe very very few people dynamically generate some large patterns. > However, \g<...> is not accepted in a pattern. > in the "regex" module I added support for it in a pattern too. Yes, backreference number in pattern also can't >= 100 Support \g<...> in pattern is a good idea. If fix this issue, may produce backward compatibility issue: the parser will confuse backreference numbers and octal escape numbers. Maybe can clarify the limit (<=99) in the document is enough. |
|||
| msg355354 - (view) | Author: Vedran Čačić (veky) * | Date: 2019-10-25 06:51 | |
I have no problem with long regexes. But those are not only long, those must be _deeply nested_ regexes, where simply 100 is an arbitrary limit. I'm quite sure if you really need depth 100, you must also need a dynamic depth of nesting, which you cannot really achieve with regexes. Yes, if there is a will to change this, supporting \g would be a way to go. |
|||
| msg355355 - (view) | Author: veaba (veaba) | Date: 2019-10-25 07:24 | |
Yes, this is not a good place to use regular expressions.
Using regular expressions:
def actual_re_demo():
import re
# This is an indefinite string...
text = "tf.where(condition, x=None, y=None, name=None) tf.batch_gather ..."
# Converting fields that need to be matched into regular expressions is also an indefinite string
pattern_str = re.compile('(tf\\.batch_gather)|(None)|(a1)')
#I don't know how many, so it's over \ \ 100 \ \ n
x = re.sub(pattern_str, '`'+'\\1\\2'+'`', text)
print(x)
# hope if:tf.Prefix needs to match,The result will be:`tf.xx`,
# But in fact, it's not just TF. As a prefix, it's a random character, it can be a suffix, it can be other characters.
# If more than 100, the result is=>:989¡¢£¤¥¦§89¨©ª«¬®¯89°±²³´µ¶·89¸¹º»¼½¾¿890123`, name=`None@ABCDEFG89HIJKLMNO89PQRSTUVW89XYZ[\]^_89`abcdefg89hijklmno89pqrstuvw89xyz{|}~8901234567890123456789
# I noticed in the comment area that it was caused by a confusion of Radix, which seems to be embarrassing.
Use replace to solve it. It looks much better.
def no_need_re():
text = "tf.where(condition, x=None, y=None, name=None) tf.batch_gather ..."
pattern_list = ['tf.batch_gather', 'None']
for item in pattern_list:
text=text.replace(item, '`'+item+'`')
print(text)
no_need_re()
Expect to report an error directly if it exceeds the limit, instead of overflowing the character, like this:
989¡¢£¤¥¦§89¨©ª«¬®¯89°±²³´µ¶·89¸¹º»¼½¾¿890123`, name=`None@ABCDEFG89HIJKLMNO89PQRSTUVW89XYZ[\]^_89`abcdefg89hijklmno89pqrstuvw89xyz{|}~8901234567890123456789
|
|||
| msg355357 - (view) | Author: Serhiy Storchaka (serhiy.storchaka) *  |
Date: 2019-10-25 08:19 | |
I do not believe somebody uses handwritten regular expressions with more than 100 groups. But if you generate regular expression, you can use named groups (?P<g12345>...) (?P=g12345). |
|||
| msg355358 - (view) | Author: veaba (veaba) | Date: 2019-10-25 08:44 | |
Aha, it's me. It's the mysterious power from the East. I just learned python. I've solved my problem. It's a very simple replace replacement, and it's solved in three lines. I'm trying to solve the problem of inadvertently finding out in the process of translating HTML text into markdown file. The document contains very complex strings, so I do that. Now it seems that the method I used before is a very inappropriate and inappropriate way to implement, which is a mistake. However, I insist that this regular overflow is still a problem. It doesn't even translate a bunch of meaningless strings without any error. I didn't find such a bug until I randomly selected and checked 2. K documents. I don't know if it's unlucky or lucky. Then, I will not participate in the discussion of the remaining high-end issues. Good luck. |
|||
| msg355359 - (view) | Author: Vedran Čačić (veky) * | Date: 2019-10-25 09:32 | |
The documentation clearly says: > This special sequence can only be used to match one of the first 99 groups. If the first digit of number is 0, or number is 3 octal digits long, it will not be interpreted as a group match, but as the character with octal value number. Maybe it should also mention Serhiy's technique at that place, something like "If you need more than 99 groups, you can name them using..." |
|||
| msg355398 - (view) | Author: Ma Lin (malin) * | Date: 2019-10-26 01:59 | |
Octal escape:
\ooo Character with octal value ooo
As in Standard C, up to three octal digits are accepted.
It only accepts UCS1 characters (ooo <= 0o377):
>>> ord('\377')
255
>>> len('\378')
2
>>> '\378' == '\37' + '8'
True
IMHO this is not useful, and creates confusions.
Maybe it can be deprecated in language level.
|
|||
| msg355399 - (view) | Author: Vedran Čačić (veky) * | Date: 2019-10-26 02:08 | |
Not very useful, surely (now that we have hex escapes). [I'd still retain \0 as a special case, since it really is useful.] But a lot more useful than a hundred backreferences. And I'm as a matter of principle opposed to changing something that's been in the language for decades for the benefit of someone that's by their own words "just learned Python". [Changing documentation is fine.] They by definition don't see the whole picture. Now that we don't have a BDFL anymore, I think it's vitally important to have some principles such as this one. |
|||
| msg355400 - (view) | Author: Ma Lin (malin) * | Date: 2019-10-26 02:21 | |
> I'd still retain \0 as a special case, since it really is useful. Yes, maybe \0 is used widely, I didn't think of it. Changing is troublesome, let's keep it as is. |
|||
| msg355401 - (view) | Author: Matthew Barnett (mrabarnett) * |
Date: 2019-10-26 02:37 | |
If we did decide to remove it, but there was still a demand for octal escapes, then I'd suggest introducing \oXXX. |
|||
| History | |||
|---|---|---|---|
| Date | User | Action | Args |
| 2022-04-11 14:59:22 | admin | set | github: 82763 |
| 2019-10-26 02:37:05 | mrabarnett | set | messages: + msg355401 |
| 2019-10-26 02:21:44 | malin | set | messages: + msg355400 |
| 2019-10-26 02:08:08 | veky | set | messages: + msg355399 |
| 2019-10-26 01:59:26 | malin | set | messages: + msg355398 |
| 2019-10-25 09:32:53 | veky | set | messages: + msg355359 |
| 2019-10-25 08:44:34 | veaba | set | messages: + msg355358 |
| 2019-10-25 08:19:05 | serhiy.storchaka | set | messages: + msg355357 |
| 2019-10-25 07:24:01 | veaba | set | messages: + msg355355 |
| 2019-10-25 06:51:17 | veky | set | messages: + msg355354 |
| 2019-10-25 05:19:34 | malin | set | messages: + msg355352 |
| 2019-10-25 01:59:15 | veaba | set | hgrepos:
+ hgrepo385 messages: + msg355350 |
| 2019-10-24 18:32:25 | veky | set | nosy:
+ veky messages: + msg355346 |
| 2019-10-24 17:15:46 | mrabarnett | set | messages: + msg355343 |
| 2019-10-24 14:19:43 | malin | set | versions:
+ Python 3.7, Python 3.8, Python 3.9 nosy: + serhiy.storchaka title: Regular match overflow -> re: backreference number in replace string can't >= 100 messages: + msg355332 |
| 2019-10-24 13:32:52 | malin | set | nosy:
+ ezio.melotti, mrabarnett messages: + msg355330 components: + Regular Expressions |
| 2019-10-24 13:10:05 | malin | set | nosy:
+ malin type: security -> |
| 2019-10-24 12:01:00 | veaba | create | |