Issue37301
This issue tracker has been migrated to GitHub,
and is currently read-only.
For more information,
see the GitHub FAQs in the Python's Developer Guide.
Created on 2019-06-16 03:38 by vsbogd, last changed 2022-04-11 14:59 by admin.
| Files | ||||
|---|---|---|---|---|
| File name | Uploaded | Description | Edit | |
| test_cgi.zip | vsbogd, 2019-06-16 03:38 | |||
| image.PNG | shajianrui, 2019-06-19 16:04 | Reproduce result. | ||
{kind=link}
| Messages (10) | |||
|---|---|---|---|
| msg345724 - (view) | Author: (vsbogd) | Date: 2019-06-16 03:38 | |
Steps to reproduce: Use POST request with "multipart/form-data" encoding to pass long (more than 64KiB) file to the CGI script. Expected result: Script receives the whole file. Actual result: Script receives only first part which size is about size of the TCP packet. Scripts to test issue are attached. To run test execute: $ python test_cgi_server.py & $ python test_cgi_client.py $ kill %1 |
|||
| msg345725 - (view) | Author: (vsbogd) | Date: 2019-06-16 03:50 | |
Analysis: self.rfile.read(nbytes) https://github.com/python/cpython/blob/3a1d50e7e573efb577714146bed5c03b9c95f466/Lib/http/server.py#L1207 Doesn't read full content of the file but only first chunk because self.rfile is not BufferedIO instance. In fact it is SocketIO instance. The reason is that CGIHTTPServer sets rbufsize to 0: # Make rfile unbuffered -- we need to read one line and then pass # the rest to a subprocess, so we can't use buffered input. rbufsize = 0 https://github.com/python/cpython/blob/3a1d50e7e573efb577714146bed5c03b9c95f466/Lib/http/server.py#L975-L977 So the minimal fix is to set rbufsize back to -1 again. This fix requires one more change, because code below: # throw away additional data [see bug #427345] while select.select([self.rfile._sock], [], [], 0)[0]: if not self.rfile._sock.recv(1): break https://github.com/python/cpython/blob/3a1d50e7e573efb577714146bed5c03b9c95f466/Lib/http/server.py#L1210-L1213 expects self.rfile instance to be SocketIO. This could be fixed by replacing this code by: So the minimal fix is to set rbufsize back to -1 again. This fix requires one more change, because code below: # throw away additional data [see bug #427345] while select.select([self.rfile], [], [], 0)[0]: if not self.rfile.read(1): break like it is implemented in another branch of the condition check: https://github.com/python/cpython/blob/3a1d50e7e573efb577714146bed5c03b9c95f466/Lib/http/server.py#L1163-L1166 |
|||
| msg345740 - (view) | Author: shajianrui (shajianrui) | Date: 2019-06-16 10:28 | |
I have the same problem, and use a similar walk-around:
1. I set the rbufsize to -1
2. I use self.connection.recv instead of self.rfile.read(), like this:
while select.select([self.connection], [], [], 0)[0]:
if not self.connection.recv(1):
However, when I go through the code, I find that at line 967 in server.py(I am using python 3.7), there is a comment:
# Make rfile unbuffered -- we need to read one line and then pass
# the rest to a subprocess, so we can't use buffered input.
rbufsize = 0
Seems for some reasons the author set rfile unbuffered, and I know nothing about it.
If you know much about it, please give me some hints, thank you.
|
|||
| msg345835 - (view) | Author: (vsbogd) | Date: 2019-06-17 09:52 | |
Yeah, I have seen this comment as well. As I see this code for the first time I am not very familiar with it.
It seems that this explanation is related to the case when non-Python CGI script is executed:
os.dup2(self.rfile.fileno(), 0)
os.dup2(self.wfile.fileno(), 1)
os.execve(scriptfile, args, env)
https://github.com/python/cpython/blob/3a1d50e7e573efb577714146bed5c03b9c95f466/Lib/http/server.py#L1176-L1178
On one hand the comment seems reasonable: as fileno is duped one cannot just read from it ahead of time. On the other hand few lines earlier one can see:
# throw away additional data [see bug #427345]
while select.select([self.rfile], [], [], 0)[0]:
if not self.rfile.read(1):
break
https://github.com/python/cpython/blob/3a1d50e7e573efb577714146bed5c03b9c95f466/Lib/http/server.py#L1163-L1166
which also seems like reading ahead of time.
My opinion this case should be tested after fix and if it works then fix can be applied without hesitation.
|
|||
| msg346021 - (view) | Author: shajianrui (shajianrui) | Date: 2019-06-19 05:22 | |
@vsbogd,Thank you for your reply. But I find another problem.
I derive a subclass from sockerserver.StreamRequestHandler, and set the rbufsize to 0(As CGIHTTPRequestHandler do), like this demo below:
testserver.py:
import socketserver
class TestRequestHandler(socketserver.StreamRequestHandler):
rbufsize = 0 ###simulate CGIHTTPRequestHandler
def handle(self):
while True:
data = self.rfile.read(65536*1024) ###client should send 65536*1024 bytes.
print(len(data))
if len(data) == 0:
print("Connection closed.")
break
s = socketserver.TCPServer(("0.0.0.0", 8001), TestRequestHandler)
s.serve_forever()
testclient.py:
import socket
data = bytearray(65536*1024)
for i in range(65536*1024):
data[i] = 64 #Whatever you set.
c = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
c.connect(("127.0.0.1", 8001))
c.send(data)
The testserver.py can get the whole 65536*1024 data in every "data = self.rfile.read(65536*1024)" line. The normal output of testserver.py is:
testserver.py output:
67108864
0
Connection closed.
67108864
0
Connection closed.
In other words, this problem of "rfile.read(nbytes)" cannot be reproduce in this demo.
I dont know why, it seems this is not only the problem of the "rfile.read(nbytes)". I guess the CGIHTTPRequestHandler actually do something that make the "rfile.read(nbytes)" perform weirdly. However, I fail to find such a line in the code.
|
|||
| msg346031 - (view) | Author: (vsbogd) | Date: 2019-06-19 08:49 | |
Hmm, seems strange I will try to reproduce and look at it. Have you run my demo which is attached to the bug? Does it reproduce problem on your machine? |
|||
| msg346061 - (view) | Author: shajianrui (shajianrui) | Date: 2019-06-19 16:04 | |
Yes I reproduce this problem with a slight modification to your demo.
Using your origianl version I fail to reproduce, maybe 2*65536 bytes size is too small.
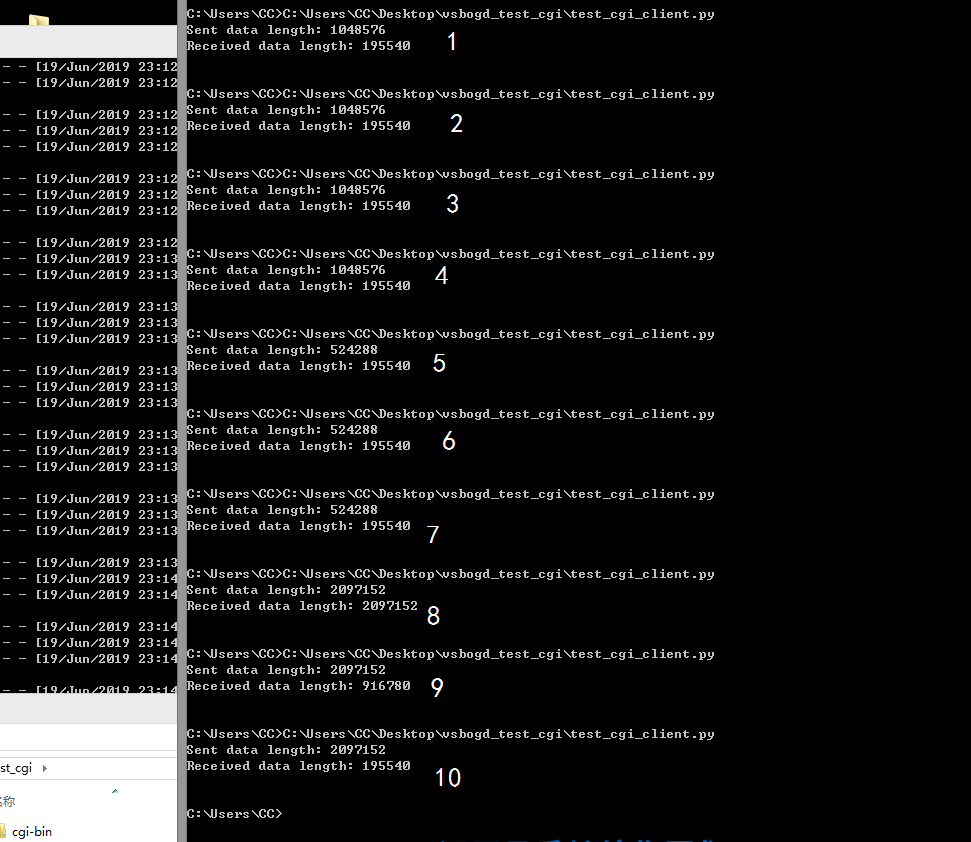
I just change the size of data (in test_cgi_client.py ) to 8*65536, 16*65536 and 32*65536, and the result is shown on the image I attach.
From the image you can see
- From 1 to 7 the length received doesn't change: always
195540 bytes.And the process of sending are really slow.
- At 8th test the server receive complete data. And the
sending is finished in a flash.(Maybe the socket suddenly
enlarge the buffer?)
- From 9 to 10 seems the "buffer" become smaller and smaller.
However, in my demo(Post in my last message), the data can be up to 65536*1024 bytes and 【seldom】 produce this problem.
I use "seldom" because I now confirm: If too many (more than 10) testclient.py are executed at the same time, the testserver.py will produce the problem too. Like this:
testserver.py output:
Connection closed.
67108864
0
Connection closed.
67108864
0
Connection closed.
67108864
0
Connection closed.
195640 # From here the problem show up.
42440740
2035240
9327940
13074300
35004
0
Connection closed.
67108864
0
Connection closed.
Seems this is a normal behavior of rfile.read() that it may not return as many bytes as we tell it to read.
Now I have a problem: Why the bytes returned from "rfile.read()" is so few when the rfile is in CGIHTTPRequestHandler?
|
|||
| msg346096 - (view) | Author: (vsbogd) | Date: 2019-06-20 04:29 | |
Hi @shajianrui, Thank you for such detailed explanation of experiments. As you mentioned it is a expected behavior of the io.RawIOBase.read() (see https://docs.python.org/3/library/io.html#io.RawIOBase), but io.BufferedIOBase.read() has different behavior (see https://docs.python.org/3/library/io.html#io.BufferedIOBase.read) and returns requested number of bytes (if stream is not interactive). So it is not surprising that this issue is being reproducible randomly and differently for Windows and Linux. I think it may be better reproducible in CGIHTTPRequestHandler because it reads header of the request first. |
|||
| msg346098 - (view) | Author: (vsbogd) | Date: 2019-06-20 05:12 | |
My last comment was imprecise. Not `CGIHTTPRequestHandler` reads data from `rfile` but CGI script itself makes few reads. |
|||
| msg346294 - (view) | Author: shajianrui (shajianrui) | Date: 2019-06-22 19:53 | |
Sorry for replying so late, and thank you very much for your reply and explanation.
At first reply to you last post: I think at least in the non-unix environment, the CGIHTTPRequestHandler read the whole(expected) data from rfile and then transfer it to the CGI script.
And considering the code for Unix environment, I dont think to set the rbufsize to -1 is a good idea. I prefer a safer way: to do a read() loop and read until nbytes received. It is much slower but more compatible. Like this:
if self.command.lower() == "post" and nbytes > 0:
#data = self.rfile.read(nbytes) #Original code at line 1199
databuf = bytearray(nbytes)
datacount = 0
while datacount + 1 < nbytes:
buf = self.rfile.read(self.request.getsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF)) #You can set your number.
if len(buf) == 0:
print("Connection closed before nbytes reached.")
break
for i in range(len(buf)):
databuf[datacount] = buf[i]
datacount += 1
if datacount == nbytes:
break
data = bytes(databuf)
This code is only for explanation... Not for use...
|
|||
| History | |||
|---|---|---|---|
| Date | User | Action | Args |
| 2022-04-11 14:59:16 | admin | set | github: 81482 |
| 2019-06-22 19:53:17 | shajianrui | set | messages: + msg346294 |
| 2019-06-20 05:12:50 | vsbogd | set | messages: + msg346098 |
| 2019-06-20 04:29:34 | vsbogd | set | messages: + msg346096 |
| 2019-06-19 16:04:36 | shajianrui | set | files:
+ image.PNG messages: + msg346061 |
| 2019-06-19 08:49:36 | vsbogd | set | messages: + msg346031 |
| 2019-06-19 05:22:40 | shajianrui | set | messages: + msg346021 |
| 2019-06-17 09:52:41 | vsbogd | set | messages: + msg345835 |
| 2019-06-16 10:42:36 | SilentGhost | set | nosy:
+ georg.brandl |
| 2019-06-16 10:28:00 | shajianrui | set | nosy:
+ shajianrui messages: + msg345740 |
| 2019-06-16 03:50:37 | vsbogd | set | messages: + msg345725 |
| 2019-06-16 03:38:49 | vsbogd | create | |