Issue35748
This issue tracker has been migrated to GitHub,
and is currently read-only.
For more information,
see the GitHub FAQs in the Python's Developer Guide.
Created on 2019-01-16 07:45 by nsonaniya2010, last changed 2022-04-11 14:59 by admin.
| Files | ||||
|---|---|---|---|---|
| File name | Uploaded | Description | Edit | |
| Screenshot from 2019-01-16 12-47-22.png | nsonaniya2010, 2019-01-16 07:45 | |||
{kind=link}
| Messages (10) | |||
|---|---|---|---|
| msg333750 - (view) | Author: Neeraj Sonaniya (nsonaniya2010) | Date: 2019-01-16 07:45 | |
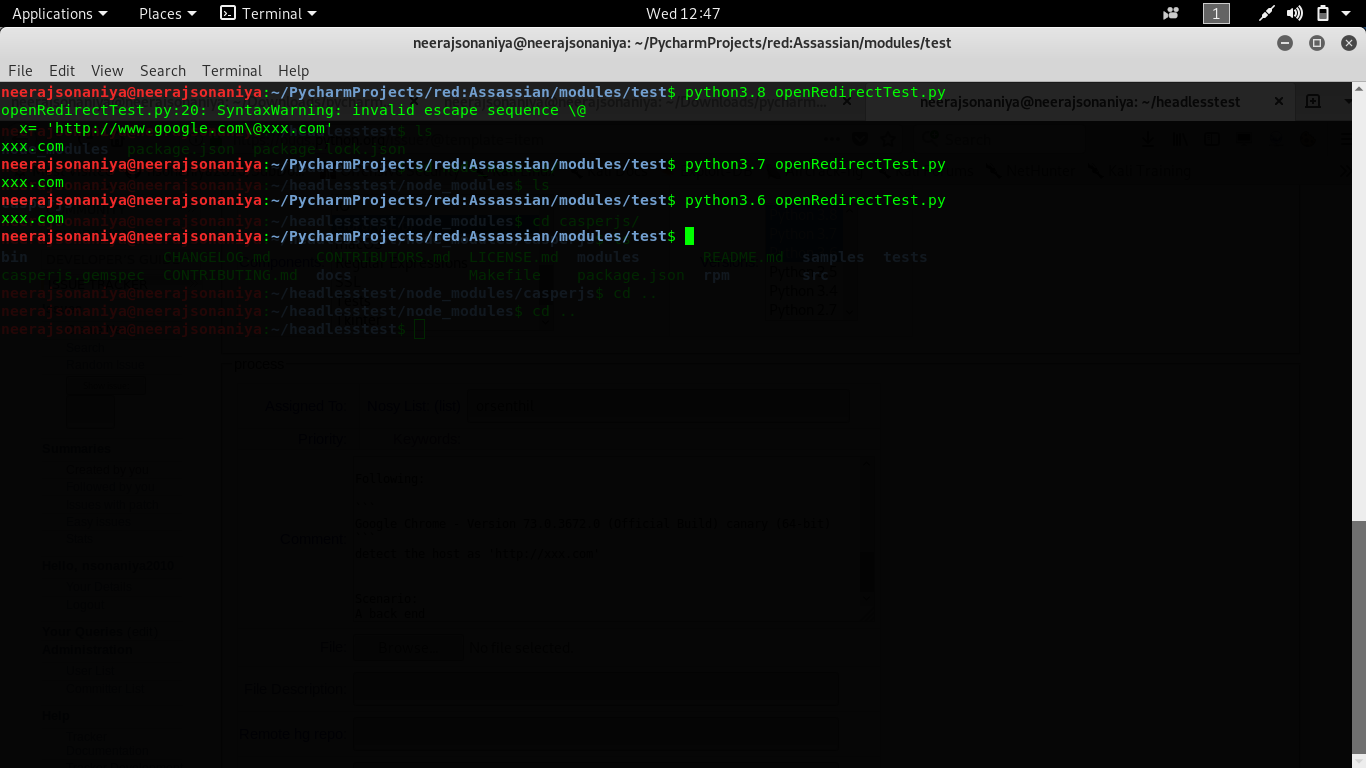
Summary: It have been identified that `urlparse` under `urllib.parse` module is detecting wrong hostname which could leads to a security issue known as Open redirect vulnerability. Steps to reproduce the issue: Following code will help you in reproducing the issue: ``` from urllib.parse import urlparse x= 'http://www.google.com\@xxx.com' y = urlparse(x) print(y.hostname) ``` Output: xxx.com The hostname from above URL which is actually rendered by browser is : 'https://www.google.com'. In following browsers tested: (hostname detected as: https://www.google.com) ``` 1. Chromium - Version 72.0.3626.7 - Developer Build 2. Firefox - 60.4.0esr (64-bit) 3. Internet Explorer - 11.0.9600.17843 4. Safari - Version 12.0.2 (14606.3.4) ``` |
|||
| msg333755 - (view) | Author: Martin Panter (martin.panter) *  |
Date: 2019-01-16 10:01 | |
FWIW I understand the backslash should be percent-encoded in URLs, otherwise the URL is not valid. This reminds me of a few other bugs: * Issue 30500: Made the behaviour of fragment (#. . .) versus userinfo (. . .@) consistent, e.g. in //www.google.com#@xxx.com * Issue 18140: Also about the ambiguity of fragment (#. . .) and query (?. . .) versus userinfo (. . .@) * Issue 23328: Precedence of path segment (/. . .) versus userinfo (. . .@); e.g. //user/name:pass/word@www.google.com I think people some times come up with these invalid URLs because they are trying to make a URL that includes a password with unusual characters (e.g. for the “http_proxy” environment variable). So raising an exception or otherwise changing the parsing behaviour could break those cases. |
|||
| msg333756 - (view) | Author: Neeraj Sonaniya (nsonaniya2010) | Date: 2019-01-16 10:04 | |
Hi, I know that \ (backslash) should be encoded to url encoding (%5c) but if the same url (without urlencoded form) typed into URL bar of browser we are getting hostname to 'https://www.google.com' |
|||
| msg333757 - (view) | Author: Christian Heimes (christian.heimes) * |
Date: 2019-01-16 10:17 | |
You cannot compare a low level library like Python's urllib module with a user interface like a modern browser. Browsers do a lot of extra work to make sense of user input. For example Firefox and Chrome mangle your example URL and replace \ with /. Firefox even shows a warning when the URL contains user and password: --- You are about to log in to the site “python.org” with the username “user”, but the website does not require authentication. This may be an attempt to trick you. Is “python.org” the site you want to visit? --- |
|||
| msg333758 - (view) | Author: Karthikeyan Singaravelan (xtreak) * |
Date: 2019-01-16 10:32 | |
I just tested other implementations in Ruby and Go and they too return host as "evil.com" for "http://www.google.com@evil.com" along with the user info component. $ ruby -e 'require "uri"; puts URI("http://www.google.com@evil.com").hostname' evil.com $ cat /tmp/foo.go package main import ( "fmt" "net/url" ) func main() { u, _ := url.Parse(`http://www.google.com@evil.com`) fmt.Println(u.Host); fmt.Println(u.User); } $ go run /tmp/foo.go evil.com www.google.com |
|||
| msg333766 - (view) | Author: Karthikeyan Singaravelan (xtreak) * |
Date: 2019-01-16 13:04 | |
There are also some notes at https://tools.ietf.org/html/rfc3986#section-7.6 Because the userinfo subcomponent is rarely used and appears before the host in the authority component, it can be used to construct a URI intended to mislead a human user by appearing to identify one (trusted) naming authority while actually identifying a different authority hidden behind the noise. For example ftp://cnn.example.com&story=breaking_news@10.0.0.1/top_story.htm might lead a human user to assume that the host is 'cnn.example.com', whereas it is actually '10.0.0.1'. Note that a misleading userinfo subcomponent could be much longer than the example above. A misleading URI, such as that above, is an attack on the user's preconceived notions about the meaning of a URI rather than an attack on the software itself. User agents may be able to reduce the impact of such attacks by distinguishing the various components of the URI when they are rendered, such as by using a different color or tone to render userinfo if any is present, though there is no panacea. More information on URI-based semantic attacks can be found in [Siedzik] In Firefox nightly and latest chrome pasting the above URL makes a request to 10.0.0.1/top_story.htm where in Chrome the URL in the address bar is changed to 10.0.0.1/top_story.htm and Firefox has the same URL in the address bar. Python also returns '10.0.0.1' as the hostname for the above example using urlparse. |
|||
| msg334032 - (view) | Author: Steven D'Aprano (steven.daprano) * |
Date: 2019-01-19 05:34 | |
I believe that Python's behaviour here is correct. You are supplying a netloc which includes a username "www.google.com\" with no password. That might be what you intend to do, or it might be malicious data. That depends on context, and the urlparse module can't tell what the context is and has no reason to assume malice. If I am reading this correctly: https://tools.ietf.org/html/rfc1738#section-3.1 the colon after the username can be omitted, so the URL is legal and Python has returned the correct value for the netloc. As Christian says, Python is not an end-user application like a browser. It is right and proper for a browser to expect that the user is non-technical and may not have noticed the @ sign, and to expect malicious behaviour, or to assume that backslash \ is a typo for forward slash / but Python programmers by definition are technical users and it is their responsibility to validate their data. There are legitimate uses for the userinfo component (user:password@hostname) and it is not the library's responsibility to assume that backslashes are typos for forward slashes. So I think that the behaviour here is correct, and this should be closed. But if you disagree, please explain what you think the library should do, and why. WHen you do, remember that: * there are legitimate users for user:password@hostname; * either the user name or the password can contain backslashes. |
|||
| msg334043 - (view) | Author: Martin Panter (martin.panter) * |
Date: 2019-01-19 07:09 | |
The “urllib.parse” module generally follows RFC 3986, which does not allow a literal backslash in the “userinfo” part:
userinfo = *( unreserved / pct-encoded / sub-delims / ":" )
unreserved = ALPHA / DIGIT / "-" / "." / "_" / "~"
pct-encoded = "%" HEXDIG HEXDIG
sub-delims = "!" / "$" / "&" / "'" / "(" / ")" / "*" / "+" / "," / ";" / "="
The RFC does not allow a backslash in the host name, path, query or fragment either. That is why I said the URL is not valid.
|
|||
| msg334049 - (view) | Author: Steven D'Aprano (steven.daprano) * |
Date: 2019-01-19 08:50 | |
> The “urllib.parse” module generally follows RFC 3986, which does not > allow a literal backslash in the “userinfo” part: And yet the parse() function seems to allow arbitrary unescaped characters. This is from 3.8.0a0: py> from urllib.parse import urlparse py> urlparse(r'http://spam\eggs!cheese&aardvark@evil.com').netloc 'spam\\eggs!cheese&aardvark@evil.com' py> urlparse(r'http://spam\eggs!cheese&aardvark@evil.com').hostname 'evil.com' If that's a bug, it is a separate bug to this issue. Backslash doesn't seem relevant to the security issue of userinfo being used to mislead: py> urlparse('http://www.google.com@evil.com').netloc 'www.google.com@evil.com' py> urlparse('http://www.google.com@evil.com').hostname 'evil.com' If it is relevant, can somebody explain to me how? |
|||
| msg349917 - (view) | Author: Ilya Konstantinov (Ilya Konstantinov) | Date: 2019-08-18 06:57 | |
From RFC-1738:
hostname = *[ domainlabel "." ] toplabel
domainlabel = alphadigit | alphadigit *[ alphadigit | "-" ] alphadigit
toplabel = alpha | alpha *[ alphadigit | "-" ] alphadigit
alphadigit = alpha | digit
However:
py> urlparse('https://foo\\bar/baz')
ParseResult(scheme='https', netloc='foo\\bar', path='/baz', params='', query='', fragment='')
The hostname's BNF doesn't allow for a backslash ('\\') character, so I'd expect urlparse to raise a ValueError for this "URL".
|
|||
| History | |||
|---|---|---|---|
| Date | User | Action | Args |
| 2022-04-11 14:59:10 | admin | set | github: 79929 |
| 2019-08-18 06:57:48 | Ilya Konstantinov | set | nosy:
+ Ilya Konstantinov messages: + msg349917 |
| 2019-01-19 08:50:39 | steven.daprano | set | messages: + msg334049 |
| 2019-01-19 07:09:18 | martin.panter | set | messages: + msg334043 |
| 2019-01-19 05:34:41 | steven.daprano | set | nosy:
+ steven.daprano messages: + msg334032 |
| 2019-01-16 13:04:32 | xtreak | set | messages: + msg333766 |
| 2019-01-16 10:32:03 | xtreak | set | nosy:
+ xtreak messages: + msg333758 |
| 2019-01-16 10:17:40 | christian.heimes | set | nosy:
+ christian.heimes messages: + msg333757 |
| 2019-01-16 10:04:35 | nsonaniya2010 | set | messages: + msg333756 |
| 2019-01-16 10:01:37 | martin.panter | set | messages: + msg333755 |
| 2019-01-16 09:18:29 | xtreak | set | nosy:
+ martin.panter |
| 2019-01-16 07:45:25 | nsonaniya2010 | create | |