Issue27580
This issue tracker has been migrated to GitHub,
and is currently read-only.
For more information,
see the GitHub FAQs in the Python's Developer Guide.
Created on 2016-07-21 05:02 by bobbyocean, last changed 2022-04-11 14:58 by admin. This issue is now closed.
| Files | ||||
|---|---|---|---|---|
| File name | Uploaded | Description | Edit | |
| nul.csv | skip.montanaro, 2016-07-21 14:12 | |||
| Opening_CSV.png | bobbyocean, 2016-07-21 21:16 | |||
{kind=link}
| Pull Requests | |||
|---|---|---|---|
| URL | Status | Linked | Edit |
| PR 28808 | merged | serhiy.storchaka, 2021-10-07 18:53 | |
| Messages (19) | |||
|---|---|---|---|
| msg270908 - (view) | Author: Bobby Ocean (bobbyocean) | Date: 2016-07-21 05:02 | |
I think this has been asked before, but it has been awhile and I think needs to be re-addressed.
Why doesn't the CSV module handle NULL bytes?
Let me do some examples,
ascii = [chr(n) for n in range(256)] #No errors
print(ascii) #No errors
print(dict(zip(ascii,ascii))) #No errors
open('temp','r').writelines(ascii) #No errors
f=open('temp','r')
for line in f: print(line) #No errors
f.close()
Python hsndles every ascii chr, DEL, ESC, RETURN, etc. It displays those characters, uses them as keys or values, etc.
But now try,
import csv
data = csv.DictReader(ascii)
for line in data: print(line) #NULL Byte Error
But we can quick fix this easily,
ascii.pop(0)
data = csv.DictReader(ascii)
for line in data: print(line) #No Errors
Doesn't it seem odd that we allow the use of every chr as keys, vslues, prints, etc. but then we hold a special exception for using the csv module and yhat special exception is not the ESC or DEL or any other non-printable chr, the exception is for the NULL?
|
|||
| msg270923 - (view) | Author: R. David Murray (r.david.murray) *  |
Date: 2016-07-21 13:40 | |
By "discussed before" I presume you are referring to issue 1599055. It is true that have been changes since then in Python's handling of null bytes. Perhaps it is indeed time to revisit this. I'll leave that to the experts...this can be closed as a duplicate of issue 1599055 if I'm wrong about things having possibly changed in the interim. |
|||
| msg270926 - (view) | Author: Skip Montanaro (skip.montanaro) *  |
Date: 2016-07-21 14:12 | |
Beyond whether or not the csv module can handle NUL bytes, you might figure out if Excel will. Since the CSV format isn't some sort of "standard", its operational definition has always been what Excel will produce or consume. I don't have Excel (not a Windows guy), but I do have Gnumeric and LibreOffice. I constructed a simple CSV file by hand which contains several NUL bytes to see what they would do. Gnumeric pops up a dialog and converts them to spaces (and then, oddly enough, doesn't think the file has been modified). LibreOffice didn't complain while loading the file, but when I saved it, it silently deleted the NULs. I've attached the file should anyone like to experiment with other spreadsheets. |
|||
| msg270939 - (view) | Author: Bobby Ocean (bobbyocean) | Date: 2016-07-21 16:14 | |
@ Skip Montanaro, Actually, CSV has nothing to do with excel. Excel is a gui that processes CSV like many other programs. CSV stands for comma seperated values and is basic standard for data.https://en.m.wikipedia.org/wiki/Comma-separated_values As far as I know, many programs handle NULL bytes fine (either as a empty atring or a # or something else). In any case, it really should be irrelevent how some particular programs handle a CSV file. |
|||
| msg270945 - (view) | Author: R. David Murray (r.david.murray) * |
Date: 2016-07-21 17:11 | |
Bobby: Skip is one of the authors of the csv module, and has been maintaining it since it was added to the standard library. He knows whereof he speaks: there is no standard for csv (as noted in the article you link), and all csv parsers that want to be interoperable refer back to Microsoft's implementation when dealing with any quirks. That implementation currently is Excel. That said, your are right that others have adopted the format, and there is an argument to be made that we don't have to *limit* ourselves to what Microsoft supports. Although we probably don't want to be emitting stuff that they don't without being explicit about it. |
|||
| msg270948 - (view) | Author: Bobby Ocean (bobbyocean) | Date: 2016-07-21 17:27 | |
I am sorry I must have mis-read the history part of that article. |
|||
| msg270951 - (view) | Author: Skip Montanaro (skip.montanaro) * |
Date: 2016-07-21 18:11 | |
I wasn't familiar with RFC 4180. (Or, quite possibly, I forgot I used to be familiar with it.) Note that at the bottom of the BNF definition of the file structure is the definition of TEXTDATA: TEXTDATA = %x20-21 / %x23-2B / %x2D-7E That pretty explicitly excludes NUL bytes (%x00 I think). I'd still like someone load my nul.csv file into Excel and report back what it does (or doesn't) do with it. |
|||
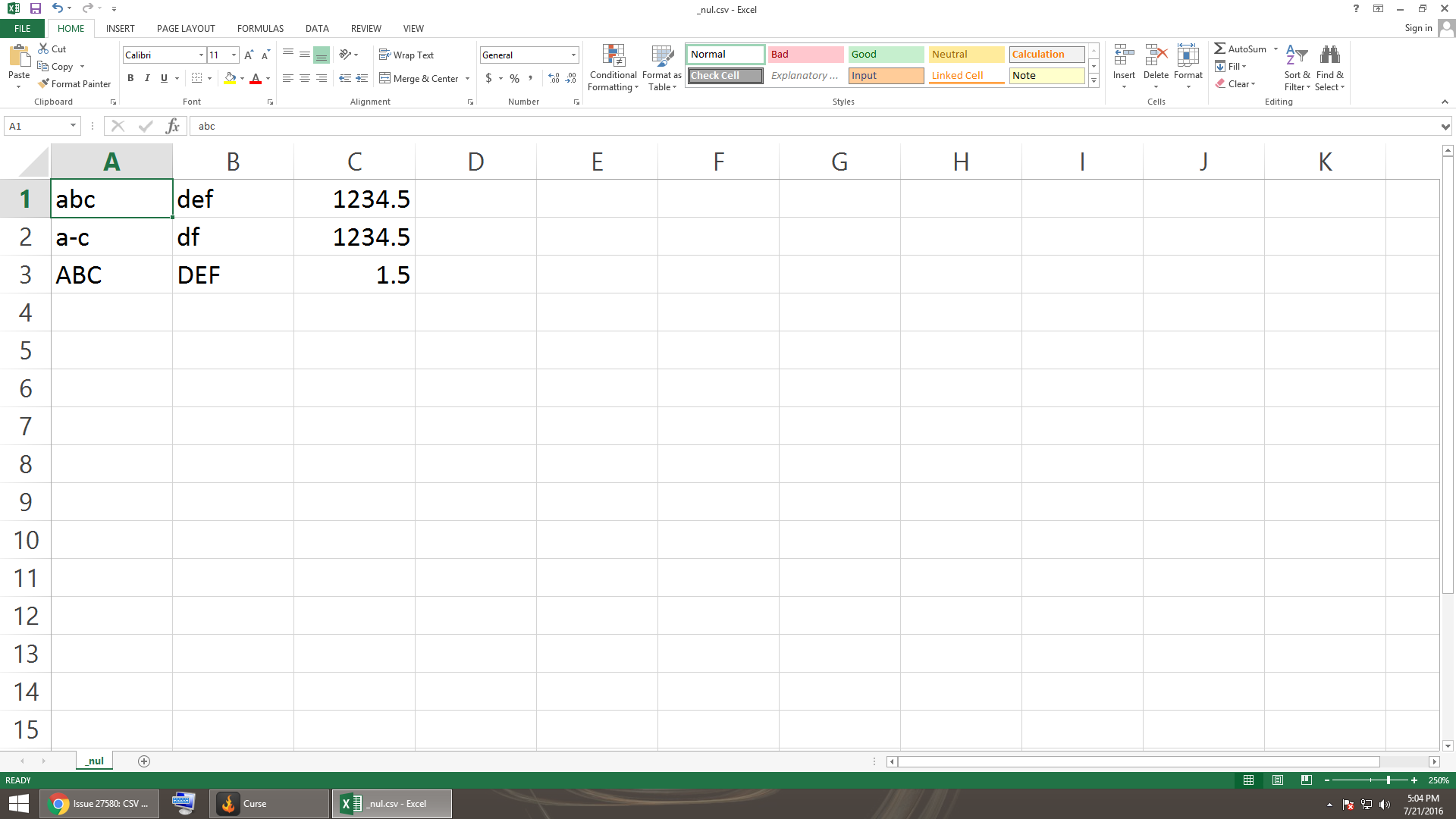
| msg270959 - (view) | Author: Bobby Ocean (bobbyocean) | Date: 2016-07-21 21:16 | |
I attempted to open the file in excel; raised no errors. In any case (regardless of Microsoft-concerns), I am glad to see a discussion started and possibly some concern that an update might be useful to the community (it would certainly cut down on the number of stack-exchange posts about this very topic). I certainly would put my vote to have csv handle the NULL byte, in the same way as python does natively. Thanks for you time. Oh, and since you are one of the author's, thanks for writing/working on the csv module, VERY USEFUL. :-) |
|||
| msg270964 - (view) | Author: Skip Montanaro (skip.montanaro) * |
Date: 2016-07-21 22:12 | |
Thanks. The display you showed looks about like I saw in LibreOffice. If you export it back to another CSV file, does the new file match the original exactly, or does (like LibreOffice) it save a file without NUL bytes? I don't mind having the discussion, but even though we have traditionally treated CSV files as binary files in Python (at least when I was closely involved in the 2.x days), that was mostly so end-of-line sequences weren't corrupted. As others have pointed out, in 2.x Python String objects stored the data as a normal NUL-terminated pointer-to-char for efficiency when interacting with C libraries. C uses NUL as a string terminator, so we couldn't work with embedded NULs. I haven't looked at the 3.x string stuff (I know Unicode is much more intimately involved). If it still maintains that close working relationship with the typical C strings, supporting NUL bytes will be problematic. In cases where the underlying representation isn't quite what I want, I've been able to get away with a file wrapper which suitably mangles the input before passing it up the chain to the csv module. For example, the __next__ method of your file wrapper could delete NULs or replace them with something suitably innocuous, like "\001", or some other non-printable character you are certain won't be in the input. If you want to preserve NULs, reverse the translation during the write(). |
|||
| msg370359 - (view) | Author: Daniel Jewell (danieljewell) | Date: 2020-05-30 06:06 | |
Forgive my frustration, but @Skip I really don't see how the definition of CSV relating to Excel (or Gnumeric or LibreOffice) has any relevance as to whether or not the module (and perhaps Python more generally) supports chr(0x00) as a delimiter. (Neither you nor I get to decide how someone else might write output data...) While the module is called CSV, it's really not just *Comma* Separated Values - rather it's a rough approximation of a database table with an optional header row where rows/records are separated by <record separator> and fields are separated by <field separator>. Sometimes the record separator is chr(0x2c) (e.g. a comma) sometimes it's chr(0x09) (e.g. a tab - or in ASCII parlance "Horizontal Tab/HT") ... or maybe even the actual ASCII "Record Separator" character (e.g. chr(0x1e)) ... or maybe NUL chr(0x00). (1) The module should be 100% agnostic about the separator - the current (3.8.3) error text when trying to use csv.reader(..., delimiter=chr(0x00)) is "TypeError: "delimiter" must be a 1-character string" ... well, chr(0x00) *is* a 1-character string. It's not a 1-character *printable* string... But then again neither is chr(0x1e) (ASCII "RS" Record Separator) .. and csv.reader(..., delimiter=chr(0x1e)) appears to work (I haven't tried actual data yet). (1a) The use of chr(0x00) or '\0' is used quite often in the *NIX world as a convenient record separator that doesn't have escaping problems because by it's very nature it's non-printable. e.g. "find . -iname "*something*" -print0 | xargs -0 <program>" ... As to the difficulty in handling 0x00 characters, I dunno ... it appears that GNU find, xargs, gawk... same with FreeBSD. FreeBSD writes the output for "-print0" like this: https://github.com/freebsd/freebsd/blob/508f3673dec94b03f89b9ce9569390d6d9b86a89/usr.bin/find/function.c#L1383 ... and bsd xargs handles it too. I haven't looked at the CPython source to see what's going on - it might be tricky to modify the code to support this... (but then again, IMHO, this sort of thing should have been a consideration in the first place....) I suppose in many ways, the very existence of this specific issue at all is just one example of what seems to be a larger issue with Python's overall development: It's a great language for *many* things and in many ways. But I've run into so many little fringe "gotchas" where something doesn't work or is limited in some way because, seemingly, functionality is designed around/defined by a practical-example-use-case and not what is or might be *possible* (e.g. the CSV-as-only-a-spreadsheet-interface example -- and I really *don't* mean that as a personal attack @Skip - I am very appreciative of the time and effort you and everyone has poured into the project...) Is it possible to write a NUL (0x00) character to a file? Through a *NIX pipe? You bet. (I got a little rant-y .. sorry... I'm sure there's a _lot_ more going on underneath the covers and there are a lot of factors - not limited to just the csv module - as you mentioned. I just really feel like something is "off". Maybe it's my brain - ha. :)) |
|||
| msg370370 - (view) | Author: Rémi Lapeyre (remi.lapeyre) * | Date: 2020-05-30 11:33 | |
I feel like the CSV module could support using NULL as separator and could send a PR with some test to add this but Daniel could you give more information regarding why you need explicit CSV support for this?
The CSV parser is needed to read and write CSV files to can be produced by other programs and has been extended to support the various dialects, most of them produced by spreadsheet programs.
> The use of chr(0x00) or '\0' is used quite often in the *NIX world as a convenient record separator that doesn't have escaping problems because by it's very nature it's non-printable. e.g. "find . -iname "*something*" -print0 | xargs -0 <program>" ...
>
> As to the difficulty in handling 0x00 characters, I dunno ... it appears that GNU find, xargs, gawk...
> Is it possible to write a NUL (0x00) character to a file? Through a *NIX pipe? You bet.
Yes and all of those are supported natively by Python already:
find . -type f -depth 1 -print0 | python -c "from pprint import pp; pp(input().split('\x00'))"
Multilines input can be supported as easily doing:
data = [
line.split('\x00')
for line in input()
]
Is this not enough?
|
|||
| msg370373 - (view) | Author: Rémi Lapeyre (remi.lapeyre) * | Date: 2020-05-30 11:40 | |
Writing to those files is obviously as easy, since like you said "because by it's very nature it's non-printable" and you will probably not find it in your data:
with open('file', 'w') as f:
f.write('\x00'.join(data))
It will break if there is a NULL byte in your data, and CSV would quote the element properly instead, but so would "find . -iname "*something*" -print0 | xargs -0 <program>" if one of the file had a NULL byte in their name.
I don't think Python is being unreasonable here, especially considering it has the same drawbacks as the other Unix utilities.
If those solutions to read and write NULL separated files are not enough for your use-case, please give more information so that it can be supported.
|
|||
| msg370376 - (view) | Author: Skip Montanaro (skip.montanaro) * |
Date: 2020-05-30 12:00 | |
I'm sorry, but why is this issue coming up again after nearly four years? Especially without a patch? (I apologize. I've gotten a bit more grumpy as I've aged.) Let me summarize a bit of history. Back in the early 2000s, Dave Cole at Object Craft in Australia implemented a C-based CSV module for Python. I don't know exactly what version was his initial target, but I have a vague memory that it was Python 1.5-ish. A few years later that was cleaned up and adapted for inclusion into the Python standard library, being added to Python 2.3. I helped with some of the Python stuff and steered it into the core. Much later (Python 3.x - with the great Unicode unification), it acquired Unicode support. At the time of creation, the only "standard" for CSV files was what Excel could read and write. One of the initial requirements as I recall was that CSV files generated by the module had to be able to survive a round trip to Excel and back. As I indicated in at least one of my previous messages to this thread, knowing how Excel handles CSV files with NUL bytes would be (at least) interesting. I still think so. Can anyone test that? I'm not trying to suggest that gracefully handling NUL bytes wouldn't be useful in certain contexts (I also use find with -print0 routinely to preserve filenames with spaces), and if the CSV module was being written from scratch today, perhaps NUL support would be included. I am happy with the current CSV module as it exists today. I still use it routinely. Adding NUL support wouldn't scratch any itch I have. If you want NUL byte support, either as a delimiter or as a character in a cell, I think you're going to have to submit a patch. Otherwise I suggest this be closed rather than languishing for another four years. |
|||
| msg370379 - (view) | Author: Skip Montanaro (skip.montanaro) * |
Date: 2020-05-30 12:28 | |
Looks like my comment removed Remi from the nosy list. Restoring that... |
|||
| msg370384 - (view) | Author: Rémi Lapeyre (remi.lapeyre) * | Date: 2020-05-30 13:25 | |
Hi Skip, I'm on a Mac so I tried Numbers, the spreadsheet tool that comes with MacOS: Opening and exporting to CSV again works: ➜ ~ cat -v ~/Documents/nul.csv abc;def;1234.5;^@^M a-c;d^@f;1234.5;^@^M ABC;DEF;1.5;^@ When exporting to TSV, it makes the correct changes: ➜ ~ cat -v ~/Documents/nul.tsv abc def 1234.5 ^M a-c d^@f 1234.5 ^@^M ABC DEF 1.5 ^@ |
|||
| msg403431 - (view) | Author: Serhiy Storchaka (serhiy.storchaka) * |
Date: 2021-10-07 19:02 | |
It looks to me that rejecting the null character is just an implementation artifact. 0 is used both as signalling value for "not set" character parameter and as the end-of-line character in the state automata. We can use different values outside of the range of Unicode characters (0-0x10ffff). It will automatically enable support of null characters. |
|||
| msg403541 - (view) | Author: Serhiy Storchaka (serhiy.storchaka) * |
Date: 2021-10-09 16:17 | |
New changeset b454e8e4df73bc73bc1a6f597431f171bfae8abd by Serhiy Storchaka in branch 'main': bpo-27580: Add support of null characters in the csv module. (GH-28808) https://github.com/python/cpython/commit/b454e8e4df73bc73bc1a6f597431f171bfae8abd |
|||
| msg407044 - (view) | Author: Petr Viktorin (petr.viktorin) * |
Date: 2021-11-26 12:22 | |
The NUL check was around for a long time, available to be used (XKCD-1172 style) as a simple check against reading binary files. The change did break tests of distutils. Maybe it deserves a What's New entry? |
|||
| msg407045 - (view) | Author: Petr Viktorin (petr.viktorin) * |
Date: 2021-11-26 12:23 | |
*docutils, not distutils |
|||
| History | |||
|---|---|---|---|
| Date | User | Action | Args |
| 2022-04-11 14:58:34 | admin | set | github: 71767 |
| 2021-11-26 12:23:14 | petr.viktorin | set | messages: + msg407045 |
| 2021-11-26 12:22:31 | petr.viktorin | set | nosy:
+ petr.viktorin messages: + msg407044 |
| 2021-10-09 16:18:43 | serhiy.storchaka | set | status: open -> closed resolution: fixed stage: patch review -> resolved |
| 2021-10-09 16:17:50 | serhiy.storchaka | set | messages: + msg403541 |
| 2021-10-07 19:02:08 | serhiy.storchaka | set | messages:
+ msg403431 versions: + Python 3.11, - Python 3.6, Python 3.7, Python 3.8 |
| 2021-10-07 18:53:21 | serhiy.storchaka | set | keywords:
+ patch stage: patch review pull_requests: + pull_request27127 |
| 2020-05-30 13:25:58 | remi.lapeyre | set | messages: + msg370384 |
| 2020-05-30 12:28:54 | skip.montanaro | set | nosy:
+ remi.lapeyre messages: + msg370379 |
| 2020-05-30 12:00:39 | skip.montanaro | set | nosy:
- remi.lapeyre messages: + msg370376 |
| 2020-05-30 11:40:58 | remi.lapeyre | set | messages: + msg370373 |
| 2020-05-30 11:33:29 | remi.lapeyre | set | nosy:
+ remi.lapeyre messages: + msg370370 |
| 2020-05-30 06:06:29 | danieljewell | set | versions:
+ Python 3.7, Python 3.8 nosy: + danieljewell messages: + msg370359 type: enhancement -> behavior |
| 2016-07-21 22:12:58 | skip.montanaro | set | messages: + msg270964 |
| 2016-07-21 21:16:30 | bobbyocean | set | files:
+ Opening_CSV.png messages: + msg270959 |
| 2016-07-21 18:11:54 | skip.montanaro | set | messages: + msg270951 |
| 2016-07-21 17:27:09 | bobbyocean | set | messages: + msg270948 |
| 2016-07-21 17:11:48 | r.david.murray | set | messages: + msg270945 |
| 2016-07-21 16:14:52 | bobbyocean | set | messages: + msg270939 |
| 2016-07-21 14:12:34 | skip.montanaro | set | files:
+ nul.csv messages: + msg270926 |
| 2016-07-21 13:40:57 | r.david.murray | set | nosy:
+ r.david.murray, skip.montanaro, serhiy.storchaka messages: + msg270923 |
| 2016-07-21 09:03:57 | SilentGhost | set | versions: + Python 3.6, - Python 3.5 |
| 2016-07-21 05:02:48 | bobbyocean | create | |