|
|
msg258674 - (view) |
Author: STINNER Victor (vstinner) *  |
Date: 2016-01-20 12:37 |
The buildbot "x86 Ubuntu Shared 3.x" build 12691 failed, the previous builds succeeded. Changes:
* f97da0952a2ebe08f2e5999c7473c776c59f3a16 (issue #25982)
* 775b74e0e103f816382a0fc009b6ac51ea956750 (issue #26107)
http://buildbot.python.org/all/builders/x86%20Ubuntu%20Shared%203.x/builds/12691/steps/test/logs/stdio
======================================================================
FAIL: test_hash_effectiveness (test.test_set.TestFrozenSet)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/srv/buildbot/buildarea/3.x.bolen-ubuntu/build/Lib/test/test_set.py", line 736, in test_hash_effectiveness
self.assertGreater(4*u, t)
AssertionError: 192 not greater than 256
======================================================================
FAIL: test_hash_effectiveness (test.test_set.TestFrozenSetSubclass)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/srv/buildbot/buildarea/3.x.bolen-ubuntu/build/Lib/test/test_set.py", line 736, in test_hash_effectiveness
self.assertGreater(4*u, t)
AssertionError: 192 not greater than 256
|
|
msg258832 - (view) |
Author: STINNER Victor (vstinner) * |
Date: 2016-01-22 17:04 |
as i expected, the bug disappeared. I'm not interested to investigate a random failure which only occurred once. I close the issue.
|
|
msg264584 - (view) |
Author: Berker Peksag (berker.peksag) * |
Date: 2016-05-01 07:40 |
I just saw the same failure on s390x RHEL 3.x: http://buildbot.python.org/all/builders/s390x%20RHEL%203.x/builds/1004/steps/test/logs/stdio
======================================================================
FAIL: test_hash_effectiveness (test.test_set.TestFrozenSet)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/dje/cpython-buildarea/3.x.edelsohn-rhel-z/build/Lib/test/test_set.py", line 738, in test_hash_effectiveness
self.assertGreater(4*u, t)
AssertionError: 124 not greater than 128
======================================================================
FAIL: test_hash_effectiveness (test.test_set.TestFrozenSetSubclass)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/dje/cpython-buildarea/3.x.edelsohn-rhel-z/build/Lib/test/test_set.py", line 738, in test_hash_effectiveness
self.assertGreater(4*u, t)
AssertionError: 124 not greater than 128
It looks like the failed assert was added in 1d0038dbd8f8.
|
|
msg265005 - (view) |
Author: Serhiy Storchaka (serhiy.storchaka) * |
Date: 2016-05-06 17:54 |
I can stably reproduce this.
PYTHONHASHSEED=36 ./python -m test.regrtest -vm test_hash_effectiveness test_set
|
|
msg279094 - (view) |
Author: Martin Panter (martin.panter) * |
Date: 2016-10-21 00:51 |
I just got this failure again today. I think I have seen it once or twice before. Is the failure actually indicating a problem with Python, or is the test just too strict?
It seems that it may be like a test ensuring that a random.randint(1, 100) is never equal to 81: the probability of it failing is low, but not close enough to zero to rely on it never failing. On the other hand, a test ensuring that a 512-bit cryptographic hash doesn’t collide might be valid because the probability is low enough.
|
|
msg279096 - (view) |
Author: Tim Peters (tim.peters) * |
Date: 2016-10-21 01:50 |
I think Raymond will have to chime in. I assume this is due to the `letter_range` portion of the test suffering hash randomization dealing it a bad hand - but the underlying string hash is "supposed to be" strong regardless of seed. The
self.assertGreater(4*u, t)
AssertionError: 124 not greater than 128
failure says 128 distinct sets hashed to only u = 124/4 = 31 distinct values across their hashes' last 7 bits, and that's worth complaining about. It's way too many collisions.
It _may_ be a flaw in the set hash, or in the string hash, or just plain bad luck, but there's really no way to know which without digging into details.
|
|
msg279697 - (view) |
Author: Eric Appelt (Eric Appelt) * |
Date: 2016-10-29 20:31 |
I dug into this failure a little bit and verified that it is specifically the "letter_range" portion of the test that sporadically fails. The hash of any frozenset constructed from floats, ints, or the empty frozenset, as well as frozensets recursively containing any of the previous have deterministic hashes that don't vary with the seed.
I isolated the letter_range test for various values of n to see how often this failure generally happened. I scanned the first 10000 integers set to PYTHONHASHSEED and got the following failures:
n=2 -
n=3 -
n=4 300, 1308, 2453, 4196, 5693, 8280, 8353
n=5 4846, 5693
n=6 3974
n=7 36, 1722, 5064, 8562, 8729
n=8 2889, 5916, 5986
n=9 -
n=10 -
I checked to see the behavior of psuedorandom integers in the range 0 to 2**64-1 by making a large sample of values taken from "len({random.randint(0,2**64) & 127 for _ in range(128)})", and found that the value of "u" in the test for n=7 if the hashes really are effectively randomly distributed follows a gaussian distribution with a mean of ~81 and deviation of ~3.5. So a value of 31 would be nearly 14 deviations from the mean which seems quite unreasonable.
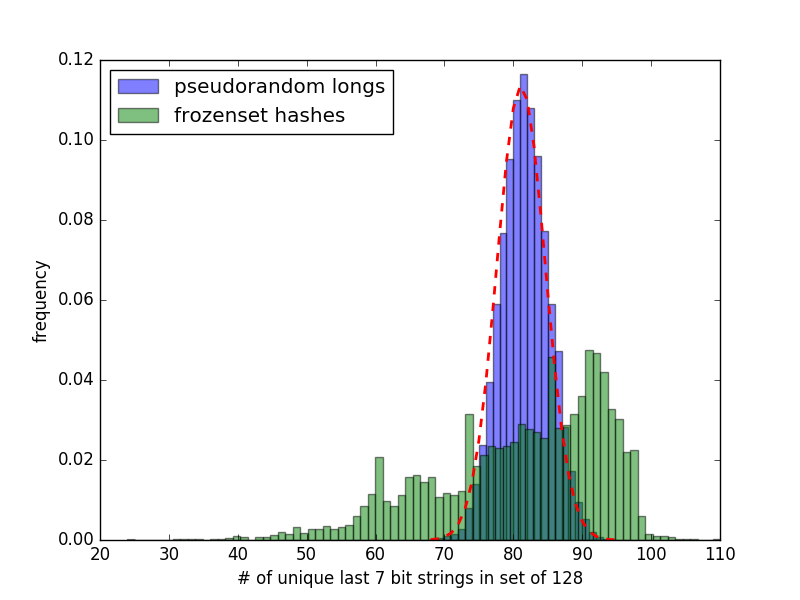
I then took the distribution of the set sizes from the letter_range test for n=7 with 10,000 different seeds and plotted it alongside the distribution of set sizes from the last 7 bits of pseudorandom numbers in the attached file "frozenset_string_n7_10k.png".
The hashes of the frozensets of single letters follows a very different distribution. Either this test is inappropriate and will cause sporadic build failures, or there is a problem with the hash algorithm.
|
|
msg279698 - (view) |
Author: Eric Appelt (Eric Appelt) * |
Date: 2016-10-29 20:37 |
I also looked at hashes of strings themselves rather than frozensets to check the hashing of strings directly.
For example, n=3:
['', 'a', 'b', 'c', 'ab', 'ac', 'bc', 'abc']
rather than:
[frozenset(), frozenset({'a'}), frozenset({'b'}), frozenset({'c'}), frozenset({'b', 'a'}), frozenset({'c', 'a'}), frozenset({'b', 'c'}), frozenset({'b', 'a', 'c'})]
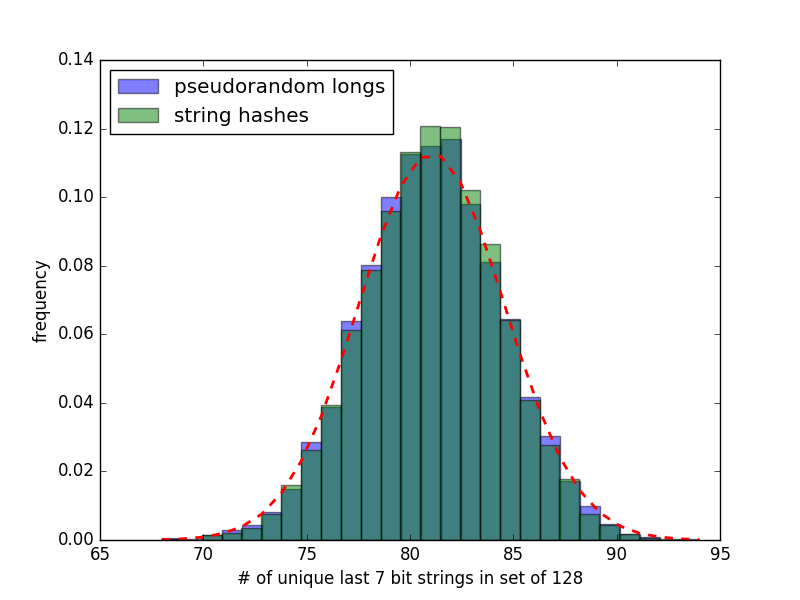
I made a distribution as with the last comment but now using the # of unique last-7 bit sequences in a set of 128 such strings (n=7) and compared to pseudorandom integers, just as was done before with frozensets of the letter combinations. This is shown in the file "str_string_n7_10k.png".
The last 7-bits of the small string hashes produce a distribution much like regular pseudorandom integers.
So if there is a problem with the hash algorithm, it appears to be related to the frozenset hashing and not strings.
|
|
msg279743 - (view) |
Author: Eric Appelt (Eric Appelt) * |
Date: 2016-10-30 19:23 |
I spent some time looking at the Objects/setobject.c code where the hashing scheme for frozensets, which essentially works by XOR-ing together the hashes from all its entries. Significant care is taken to shuffle bits at various stages, and the algorithm seems to be well thought out. My own attempts to change constants or add in reshufflings either didn't help the collision statistics or just made things worse. I think that there is something of a fundamental limitation here due to information loss in XOR, and other fast, commutative bitwise operations (i.e. AND, OR) are well known to be much worse.
I did stumble on a 2006 paper by Boneh and Boyen [1] which looked at a potentially related problem of trying to combine two different hashing functions to improve collision resistance and found that there was no way to do this with fewer bits than just concatenating the hashes. The present ticket is more a problem of combining hashes from the same function in an order-independent way and may be completely unrelated. However, I imagine that concatenation followed by rehashing the result would remove the loss due to XORing unlucky choices of hashes.
Concatenating everything seemed obviously too slow and/or unacceptable in terms of memory use, but I thought of a compromise where I would construct an array of 4 hash values, initialized to zero, and for each entry I would select an array index based on a reshuffling of the bits, and XOR that particular entry into the chosen index. This results in a hash that is 4x wider than the standard size that reduces the information loss incurred from XOR. This wide hash can then be hashed down to a normal sized hash.
I implemented this algorithm and tested it using the same procedure as before. Specifically, all frozensets for every possible combination (128) of the letters abcdefg as single character strings are hashed, and the last 7 bits of each of their hashes are compared to see how many unique 7-bit patterns are produced. This is done for PYTHONHASHSEED values from 1 to 10000 to build a distribution. The distribution is compared to a similar distribution constructed from pseudorandom numbers for comparison.
Unlike the current hashing algorithm for frozensets, and much like the result from hashes of strings, the result of this new "wide4" algorithm appears to be nearly ideal. The results are plotted in "frozenset_string_n7_10k_wide4.png" as attached.
I will follow this up with a patch for the algorithm as soon as I run the complete test suite and clean up.
Another option if the current algorithm is considered good enough is to alter the current test to retry on failure if the power set of letters 'abcdefg...' fails by shifting one letter and trying again, perhaps ensuring that 4/5 tests pass. This ought to greatly reduce the sporadic build failures.
[1] http://ai.stanford.edu/~xb/crypto06b/blackboxhash.pdf
|
|
msg279753 - (view) |
Author: Eric Appelt (Eric Appelt) * |
Date: 2016-10-30 23:14 |
Ugh... so I think I made a mental error (i.e. confused myself) in the last comment. The result looked a bit "to good to be true" and I think that there is at least one error in my thinking about the problem.
I tried testing with the width set to 2 and then 1 as a check and noticed that even without "widening" the problem was still fixed and the hash distributions matched that of pseudorandom numbers.
It turns out that just running the XORed result of the shuffled entry hashes through the hashing algorithm gets rid of any bit patterns picked up through the process. Currently there is an LCG that is used to disperse patterns but I don't think it really helps the problems arising in these tests:
hash = hash * 69069U + 907133923UL;
I'm not attaching any more plots as the result can be described in words, but when the LCG applied to the hash after XORing all entries is replaced with a hashing of the result using the standard python hashing algorithm, the test problem goes away. Specifically, when 128 distinct sets are hashed, the resulting hashes have a distribution of unique values across their last 7 digits matches the distribution from pseudorandom numbers.
The fix is implemented in a small patch that I have attached.
|
|
msg279769 - (view) |
Author: Serhiy Storchaka (serhiy.storchaka) * |
Date: 2016-10-31 08:01 |
Eric, did you tested with FNV or SipHash24 hashing algorithm?
Using standard Python hashing algorithm adds hash randomization for frozensets. This is worth at least be mentioned in What's New document.
|
|
msg279792 - (view) |
Author: Eric Appelt (Eric Appelt) * |
Date: 2016-10-31 14:43 |
If I understand the reporting properly all tests so far have used SipHash24:
Python 3.7.0a0 (default:5b33829badcc+, Oct 30 2016, 17:29:47)
[GCC 4.2.1 Compatible Apple LLVM 7.3.0 (clang-703.0.31)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import sysconfig
>>> sysconfig.get_config_var("Py_HASH_ALGORITHM")
0
>>> import sys
>>> sys.hash_info.algorithm
'siphash24'
It sounds like it is worth it for me to be more rigorous and perform a battery of tests using FNV and then SipHash24 to compare:
- Performing no dispersion after the frozenset hash is initially computed from XORing entry hashes (control)
- Performing dispersion using an LCG after the frozenset hash is initially computed from XORing entry hashes (current approach)
- Performing dispersion using the selected hash algorithm (FNV/SipHash24) after the frozenset hash is initially computed from XORing entry hashes (proposed approach)
I'll take the six plots and merge them into a single PNG, and also post my (short)testing and plotting scripts for reproducibility and checking of the results.
I can also write a regression test if you think that would be good to have in the test suite (perhaps skipped by default for time), where instead of using the same seven letters a-g as test strings and varying PYTHONHASHSEED, I could perform the letter test for n=7 with 10000 different sets of short random strings to see if any fell below threshold.
|
|
msg279886 - (view) |
Author: Eric Appelt (Eric Appelt) * |
Date: 2016-11-01 18:16 |
Here are my test results - I'll re-describe the issue and test so people don't have to read through all the previous text and for completeness.
-------------------------------------
The basic test case ("letter test"):
Consider the set of the first seven letters - {'a', 'b', 'c', 'd', 'e', 'f', 'g'}. If one constructs frozensets of all 128 possible subsets of this set, and computes their hashes, in principle they should have good collision statistics.
To check, the hashes of all 128 frozensets are computed and the last 7 bits of each hash are compared. The quality of the hashing algorithm is indicated by how many unique values of the last 7 bits are present in the set of 128 hashes. Too few unique values and the collision statistics are poor.
In the python testing suite, this particular test is run and if the number of unique values is 32 or less the test fails. Since the hash of a string depends on the value of the PYTHONHASHSEED which is random by default, and the hashes of frozensets are dependent on their entries, this test is not deterministic. My earlier tests show that this will fail for one out of every few thousand seeds.
--------------------------
The implementation issue and proposed fix:
The hash of a frozen set is computed by taking the hash of each element, shuffling the bits in a deterministic way, and then XORing it into a hash for the frozenset (starting with zero). The size of the frozenset is then also shuffled and XORed into that result.
Finally, in order to try to remove patterns incurred by XORing similar combinations of elements as with nested sets, the resulting hash is sent through a simple LCG to arrive at a final value:
hash = hash * 69069U + 907133923UL;
The hypothesis is that this LCG is not effective in improving collision rates for this particular test case. As an alternative, the proposal is to take the result of the XORs, and run that through the hashing algorithm set in the compiled python executable for hashing bytes (i.e. FNV or SipHash24). This rehashing may do a better job of removing patterns set up by combinations of common elements.
-------------------------------------
The experiment:
To more robustly check the properties of the frozenset hashing algorithm, the letter test is run many times setting different PYTHONHASHSEED values from 0 to 10000. This produces a distribution of unique sequences (u) of the last 7 hash bits in the set of 128 frozensets.
To compare against the optimal case, the same distribution (u) is produced from a set of pseudorandom integers generated with "random.randint(0, 2**64)". Which is found to have be a normal distribution with a mean of ~81 and standard deviation of ~3.5.
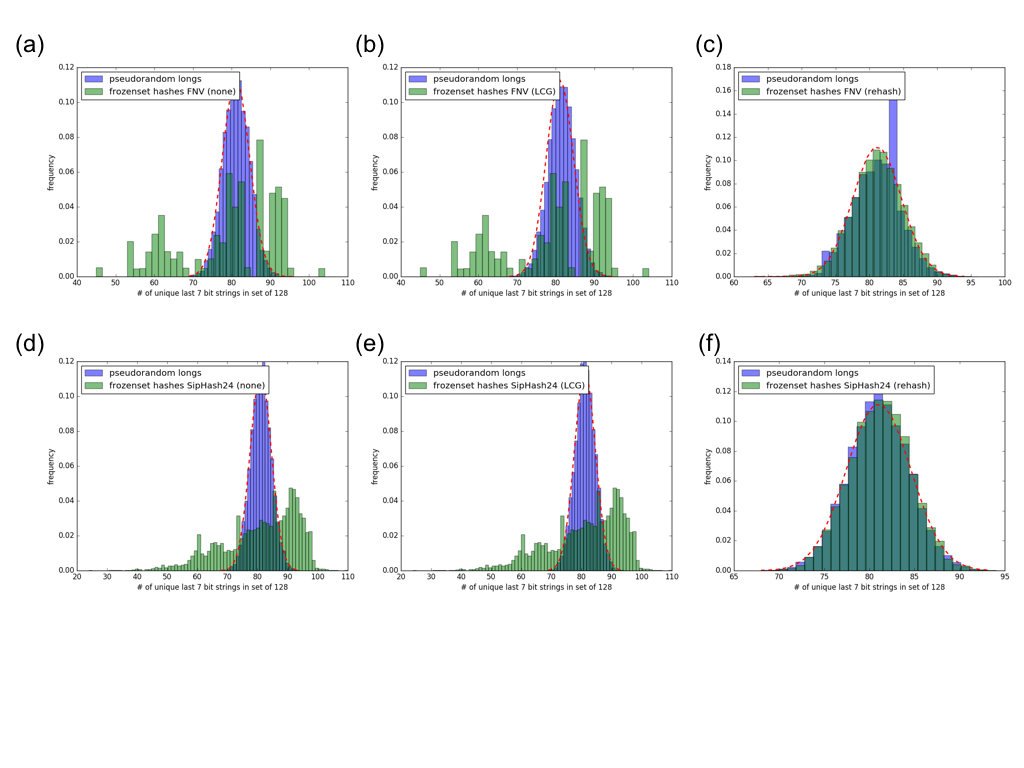
Six different test cases are considered and the results are shown in the attached figure (figure1.png)
- Compile using the FNV algorithm. For control, do not shuffle the XORed result to compute the frozenset hash. (Fig 1-a)
- Compile using the FNV algorithm. For the current implementation, shuffle the XORed result using the LCG to compute the frozenset hash. (Fig 1-b)
- Compile using the FNV algorithm. For the current implementation, shuffle the XORed result using the FNV algorithm to compute the frozenset hash. (Fig 1-c)
- Compile using the SipHash24 algorithm. For control, do not shuffle the XORed result to compute the frozenset hash. (Fig 1-d)
- Compile using the SipHash24 algorithm. For the current implementation, shuffle the XORed result using the LCG to compute the frozenset hash. (Fig 1-e)
- Compile using the SipHash24 algorithm. For the current implementation, shuffle the XORed result using the SipHash24 algorithm to compute the frozenset hash. (Fig 1-f)
--------------------------------
Results:
Using the LCG to shuffle the XORed result of the entry and size hashes to finish computing the frozenset hash did not improve the results of the letter test, and appeared to have no effect on the distribution at all.
Rehashing with the configured algorithm to shuffle the XORed result of the entry and size hashes to finish computing the frozenset hash did not improve the results of the letter test, and appeared to have no effect on the distribution at all.
The FNV results were odd in that specific outlying values of u were often repeated for different seeds, such as 45 and 104. There was no apparent periodic behavior in these repeated outlying results.
|
|
msg279887 - (view) |
Author: Eric Appelt (Eric Appelt) * |
Date: 2016-11-01 18:18 |
I made a copy/paste error on the second to last paragraph of the previous comment, it should be:
Rehashing with the configured algorithm to shuffle the XORed result of the entry and size hashes to finish computing the frozenset hash resulted in an ideal distribution matching that of the pseudorandom numbers.
|
|
msg281422 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2016-11-22 00:54 |
Rather than making futile further attempts to scramble the bits in the final hash to hide the effect of weak upstream hash inputs, I'm inclined to disable this particular test which was already a crazily harsh torture test. I suspect that even the tuple hash wouldn't survive variants of this test.
|
|
msg281423 - (view) |
Author: Roundup Robot (python-dev)  |
Date: 2016-11-22 00:59 |
New changeset e0f0211d314d by Raymond Hettinger in branch '3.6':
Issue #26163: Disable periodically failing test which was overly demanding of the frozenset hash function effectiveness
https://hg.python.org/cpython/rev/e0f0211d314d
|
|
msg309945 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2018-01-15 04:35 |
Bringing this tracker item back to life. I've had more time to look at the this and the underlying problem was the high bits were not being shuffled back to impact lower bits. By fixing this, all of the tests produce a greater number of distinct values than before.
|
|
msg309961 - (view) |
Author: Serhiy Storchaka (serhiy.storchaka) * |
Date: 2018-01-15 10:09 |
As far as I understand, the problem is that the value obtained by XORing hashes of elements has nonuniform distribution. Further transformations, either linear or nonlinear, as well as adding length, don't change the fact that the result of XORing contains less information than the number of bit in the hash word. The mathematically strong way of computing the hash of a frozenset is:
hash(tuple(sorted(hash(x) for x in frozenset)))
Store all hash values into an array, sort them for getting rid of ordering, and make a hash of all concatenated hashes.
But this algorithm requires linear memory and have superlinear complexity. For practical purposes we need just makes the difference of the distribution from the uniform distribution small enough. Maybe the following algorithm could help:
buckets = [0] * N
for x in frozenset:
h = hash(x)
i = shuffle_bits1(h) % N
buckets[i] ^= shuffle_bits2(h)
return hash(tuple(buckets))
where shuffle_bits1() and shuffle_bits2() are functions that shuffle bits in different ways.
|
|
msg310008 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2018-01-15 18:44 |
I'm getting a nice improvement in dispersion statistics by shuffling in higher bits right at the end:
/* Disperse patterns arising in nested frozensets */
+ hash ^= (hash >> 11) ^ (~hash >> 25);
hash = hash * 69069U + 907133923UL;
Results for range() check:
range range
baseline new
1st percentile 35.06% 40.63%
1st decile 48.03% 51.34%
mean 61.47% 63.24%
median 63.24% 65.58%
Test code for the letter_range() test:
letter letter
baseline new
1st percentile 39.59% 40.14%
1st decile 50.90% 51.07%
mean 63.02% 63.04%
median 65.21% 65.23%
def letter_range(n):
return string.ascii_letters[:n]
def powerset(s):
for i in range(len(s)+1):
yield from map(frozenset, itertools.combinations(s, i))
# range() check
for i in range(10000):
for n in range(5, 19):
t = 2 ** n
mask = t - 1
u = len({h & mask for h in map(hash, powerset(range(i, i+n)))})
print(u/t*100)
# letter_range() check needs to be restarted (reseeded on every run)
for n in range(5, 19):
t = 2 ** n
mask = t - 1
u = len({h & mask for h in map(hash, powerset(letter_range(n)))})
print(u/t)
|
|
msg310063 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2018-01-16 09:30 |
New changeset b44c5169f64178d2ff2914187b315549e7ab0cb6 by Raymond Hettinger in branch 'master':
bpo-26163: Frozenset hash improvement (#5194)
https://github.com/python/cpython/commit/b44c5169f64178d2ff2914187b315549e7ab0cb6
|
|
msg310070 - (view) |
Author: Raymond Hettinger (rhettinger) * |
Date: 2018-01-16 10:27 |
New changeset e7dbd0658304f11daf103d56662656efecad006d by Raymond Hettinger (Miss Islington (bot)) in branch '3.6':
bpo-26163: Frozenset hash improvement (GH-5194) (#5198)
https://github.com/python/cpython/commit/e7dbd0658304f11daf103d56662656efecad006d
|
|
| Date |
User |
Action |
Args |
| 2022-04-11 14:58:26 | admin | set | github: 70351 |
| 2018-01-18 21:34:49 | python-dev | set | pull_requests:
+ pull_request5082 |
| 2018-01-18 20:35:10 | rhettinger | set | pull_requests:
+ pull_request5081 |
| 2018-01-16 10:27:17 | rhettinger | set | messages:
+ msg310070 |
| 2018-01-16 09:31:49 | rhettinger | set | status: open -> closed
resolution: fixed
stage: patch review -> resolved |
| 2018-01-16 09:30:42 | python-dev | set | pull_requests:
+ pull_request5052 |
| 2018-01-16 09:30:29 | rhettinger | set | messages:
+ msg310063 |
| 2018-01-15 19:21:58 | rhettinger | set | pull_requests:
+ pull_request5048 |
| 2018-01-15 18:44:53 | rhettinger | set | messages:
+ msg310008 |
| 2018-01-15 18:43:56 | rhettinger | set | messages:
- msg310007 |
| 2018-01-15 18:42:46 | rhettinger | set | messages:
+ msg310007 |
| 2018-01-15 10:09:05 | serhiy.storchaka | set | messages:
+ msg309961 |
| 2018-01-15 08:28:03 | rhettinger | set | pull_requests:
- pull_request5041 |
| 2018-01-15 05:05:43 | rhettinger | set | stage: patch review
pull_requests:
+ pull_request5041 |
| 2018-01-15 04:35:36 | rhettinger | set | status: closed -> open
resolution: wont fix -> (no value)
messages:
+ msg309945
|
| 2016-11-22 01:00:06 | rhettinger | set | status: open -> closed
resolution: wont fix |
| 2016-11-22 00:59:40 | python-dev | set | nosy:
+ python-dev
messages:
+ msg281423
|
| 2016-11-22 00:54:51 | rhettinger | set | messages:
+ msg281422 |
| 2016-11-01 18:18:37 | Eric Appelt | set | messages:
+ msg279887 |
| 2016-11-01 18:16:53 | Eric Appelt | set | files:
+ fig1.png
messages:
+ msg279886 |
| 2016-10-31 14:43:05 | Eric Appelt | set | messages:
+ msg279792 |
| 2016-10-31 08:11:16 | christian.heimes | set | nosy:
+ christian.heimes
|
| 2016-10-31 08:01:27 | serhiy.storchaka | set | messages:
+ msg279769 |
| 2016-10-31 05:34:24 | rhettinger | set | assignee: rhettinger |
| 2016-10-30 23:14:20 | Eric Appelt | set | files:
+ setobject.c.2.patch
keywords:
+ patch
messages:
+ msg279753
|
| 2016-10-30 19:23:02 | Eric Appelt | set | files:
+ frozenset_string_n7_10k_wide4.png
messages:
+ msg279743 |
| 2016-10-29 20:37:24 | Eric Appelt | set | files:
+ str_string_n7_10k.png
messages:
+ msg279698 |
| 2016-10-29 20:31:21 | Eric Appelt | set | files:
+ frozenset_string_n7_10k.png
nosy:
+ Eric Appelt
messages:
+ msg279697
|
| 2016-10-21 01:50:22 | tim.peters | set | nosy:
+ tim.peters
messages:
+ msg279096
|
| 2016-10-21 00:51:31 | martin.panter | set | nosy:
+ martin.panter
messages:
+ msg279094
versions:
+ Python 3.7 |
| 2016-05-06 17:54:11 | serhiy.storchaka | set | nosy:
+ serhiy.storchaka
messages:
+ msg265005
|
| 2016-05-01 07:40:10 | berker.peksag | set | status: closed -> open
nosy:
+ rhettinger, berker.peksag
messages:
+ msg264584
type: behavior
resolution: out of date -> (no value) |
| 2016-01-22 17:04:57 | vstinner | set | status: open -> closed
resolution: out of date
messages:
+ msg258832
|
| 2016-01-20 12:37:44 | vstinner | create | |
{kind=link}
{kind=link}
{kind=link}
{kind=link}