Issue10399
This issue tracker has been migrated to GitHub,
and is currently read-only.
For more information,
see the GitHub FAQs in the Python's Developer Guide.
Created on 2010-11-12 20:16 by dmalcolm, last changed 2022-04-11 14:57 by admin.
| Files | ||||
|---|---|---|---|---|
| File name | Uploaded | Description | Edit | |
| py3k-ast-optimization-inlining-2010-11-12-001.patch | dmalcolm, 2010-11-12 20:16 | |||
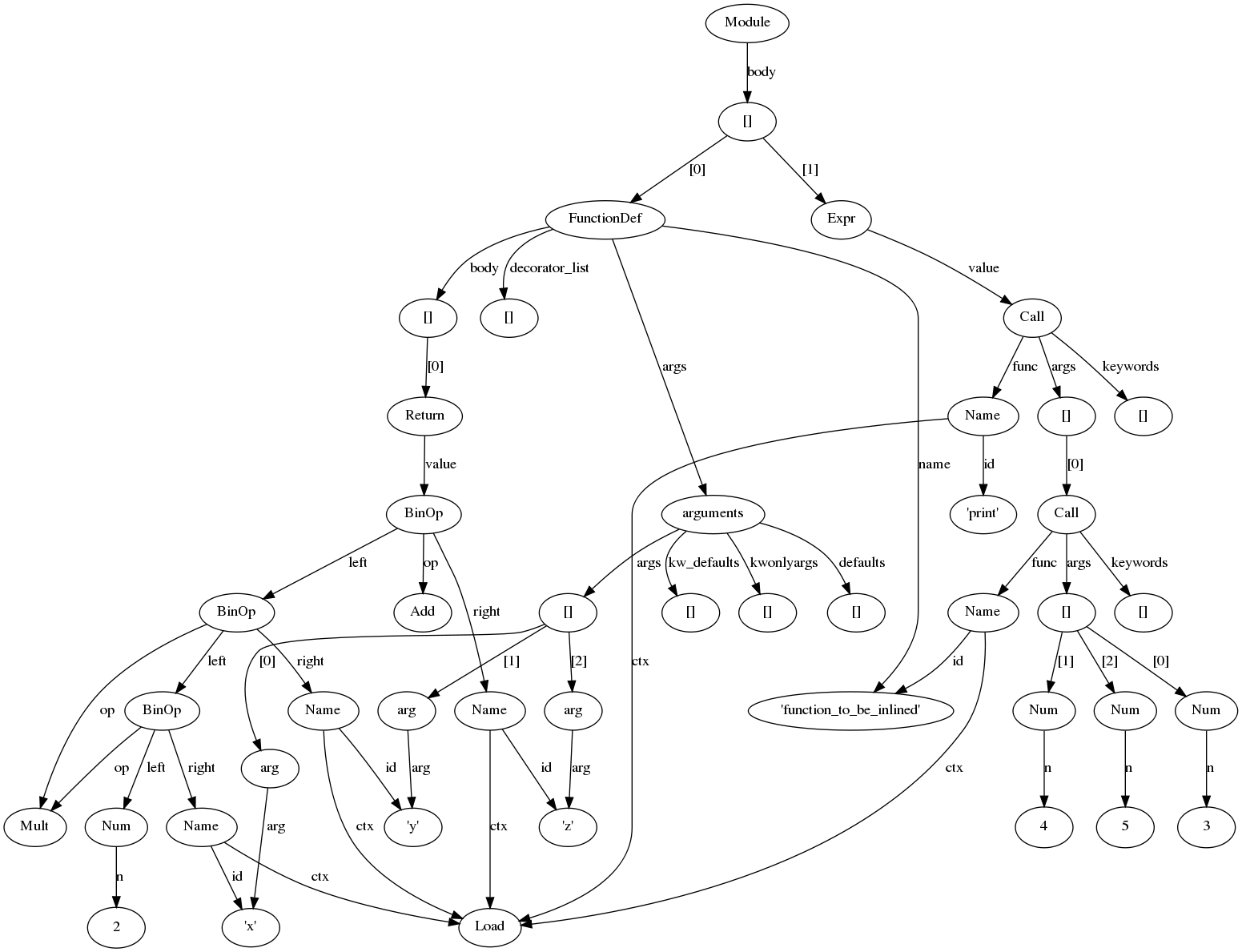
| before.png | dmalcolm, 2010-11-12 20:18 | AST of the sample source before optimization | ||
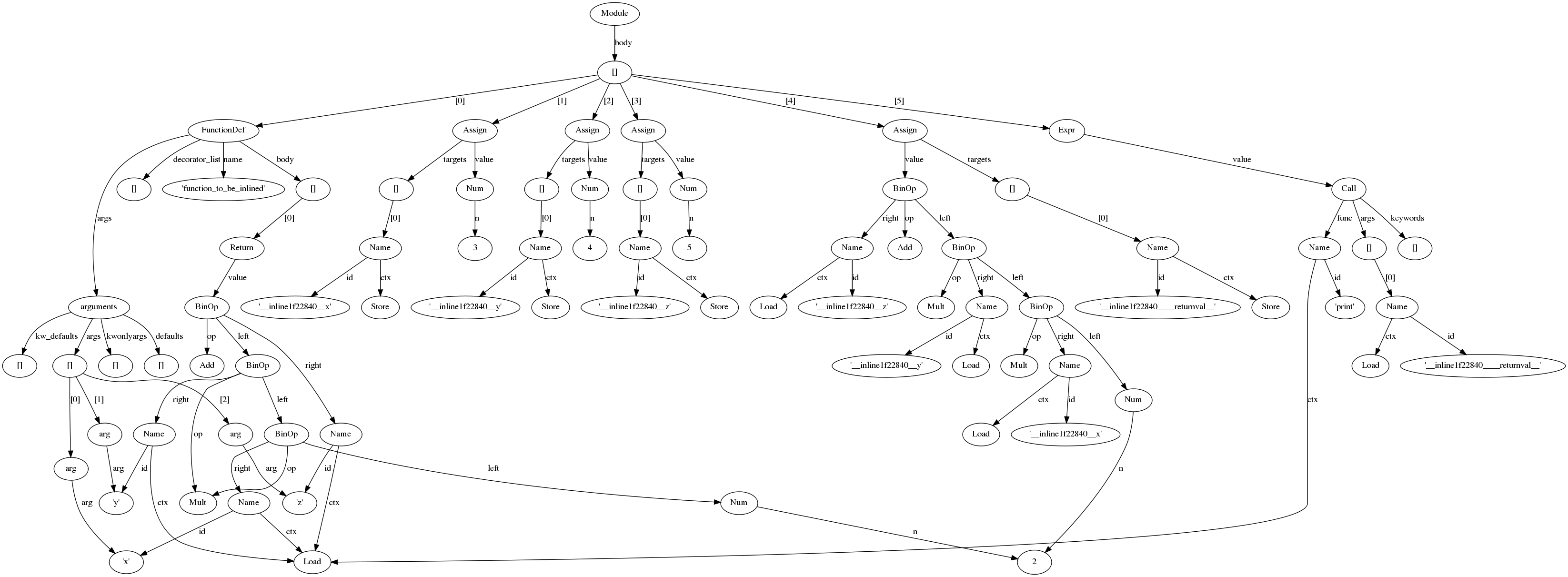
| after.png | dmalcolm, 2010-11-12 20:18 | AST of the sample source after optimization | ||
| py3k-ast-pyoptimize-2010-11-19-006.patch | dmalcolm, 2010-11-20 01:10 | |||
{kind=link}
{kind=link}
| Messages (17) | |||
|---|---|---|---|
| msg121068 - (view) | Author: Dave Malcolm (dmalcolm)  |
Date: 2010-11-12 20:16 | |
In msg#120541 of issue#1346238 Raymond suggested to "aim high", so here goes... I'm opening this as a separate bug as it's a very different approach to the patches in that bug; adding those on the nosy list for that bug. Sorry in advance about the epic length of this comment. I've been experimenting with AST optimizations, and have a (very) primitive implementation of function-call inlining. As is, it's deeply flawed, but in a spirit of "Release Early, Release Often" I though I'd post what I have so far, and try to enumerate the rest of the work that would need doing to get this into, say Python 3.3 The attached patch adds an AST optimization pass to Python/compiler.c. It does this by adding an __optimizer__.py module: the compiler converts the AST to a Python representation using ast2mod, and calls out to __optimizer__.optimize_ast(). This can then (potentially) apply a series of manipulations to the tree. The result is then converted back from python to ast objects, and compilation proceeds as normal on the modified AST tree. I initially was experimenting with a .c implementation, but moving to .py makes things _much_ easier to develop and debug. In particular, I'm using graphviz's "dot" tool to generate before/after visualizations of the AST. The optimizer doesn't try to optimize itself (or anything that it imports), to avoid infinite recursion when we have a cold .pyo cache. Currently I'm doing the AST optimization before symbol table generation. This means that the inlining is deeply flawed, as it has no knowledge of the scope of names. A robust implementation would compare the scopes of the callsite and that of the function body, and remap locals accordingly. The current implementation renames all name references in the function body, which is clearly wrong for e.g. references to globals. See below for notes on that. Here's my test code:: def function_to_be_inlined(x, y, z): return (2 * x * y) + z print(function_to_be_inlined(3, 4, 5)) Here's what it compiles to after going through the inliner (clearly, line numbering needs some work). Note the removal of the CALL_FUNCTION of our target call site; the remaining CALL_FUNCTION is to "print": 2 0 LOAD_CONST 0 (<code object function_to_be_inlined at 0x1e9b998, file "<dis>", line 2>) 3 MAKE_FUNCTION 0 6 STORE_NAME 0 (function_to_be_inlined) 4 9 LOAD_CONST 1 (3) 12 STORE_NAME 1 (__inline1f22840__x) 15 LOAD_CONST 2 (4) 18 STORE_NAME 2 (__inline1f22840__y) 21 LOAD_CONST 3 (5) 24 STORE_NAME 3 (__inline1f22840__z) 259 27 LOAD_CONST 4 (2) 30 LOAD_NAME 1 (__inline1f22840__x) 33 BINARY_MULTIPLY 34 LOAD_NAME 2 (__inline1f22840__y) 37 BINARY_MULTIPLY 38 LOAD_NAME 3 (__inline1f22840__z) 41 BINARY_ADD 42 STORE_NAME 4 (__inline1f22840____returnval__) 260 45 LOAD_NAME 5 (print) 48 LOAD_NAME 4 (__inline1f22840____returnval__) 51 CALL_FUNCTION 1 54 POP_TOP 55 LOAD_CONST 5 (None) 58 RETURN_VALUE The idea is that a further optimization pass would go through and ellide the unnecessary store-to-local/load-from-local instructions, followed by const folding, getting this down to: LOAD_CONST (<code object>) MAKE_FUNCTION STORE_NAME (function_to_be_inlined) ; inlined callsite: LOAD_NAME (print) LOAD_CONST (29) CALL_FUNCTION 1 The biggest issue here is dealing with runtime differences between which function was inlined, and which function is being called, either via monkeypatching, or in method calls - we can inline intra-method calls within one class, but we have to cope with overriding of those methods in subclasses. Thinking aloud of a way of solving this (this isn't implemented yet): add to AST: Specialize(expr name, stmt* specialized, stmt* generalized) where you have some interpretation of name (e.g. "self.do_something"), and carry two different implementations. so that e.g. class Something: def foo(self, x, y, z): ... # some code self.bar(x, y, z) ... # more code the: Call(Attribute(Name(id='self'), id='bar'), args=[etc]) becomes Specialize(name=Attribute(Name(id='self'), id='bar'), specialized=[inlined implementation of Something.bar for "self"], generalized=[Call(Attribute(Name(id='self'), id='bar'), args=[etc])]) Similarly, would need a new bytecode, say "JUMP_IF_SPECIALIZABLE" LOAD_NAME (self) GET_ATTR ('bar') ; method self.bar is now on top of stack LOAD_CONST (<code object for the regular implementation of "bar">) JUMP_IF_SPECIALIZABLE -> label_inline_body ; Start of non-inlined call eval and push args CALL_FUNCTION JUMP_ABSOLUTE -> label_after ; ...end of non-inlined call; return value is top-of-stack label_inline_body: eval args (potentially optimizing with knowledge of what's to come) inlined call push "return value" ; ...end of inlined call; "return value" is top-of-stack label_after: ; etc JUMP_IF_SPECIALIZABLE Inputs: TOS : A: code object we inlined for (via a LOAD_CONST, injected by the inliner) TOS -1 : B: function object via runtime lookup (LOAD_GLOBAL, or e.g. LOAD_LOCAL "self"; GET_ATTR "do_something") Action: if B's __code__ is A, we can specialize: PC += oparg POP else: PC += 1 POP POP I'm not sure if this covers all cases (e.g. specializing a CFunction such as the builtins), or if this a sane approach that actually works; need to have a standard interpretation of what a name lookup means, and to inject LOAD_CONST of that value into the bytecode, for use by the JUMP_IF_SPECIALIZABLE operation. As I understand it, functions are "name-resolved" before the arguments are evaluated, so if argument evaluation leads to the name being bound to a different function (as a side effect), the status quo in CPython currently is that the old function is used for that call; JUMP_IF_SPECIALIZABLE would preserve that behavior. It could also slightly slow down overridden method calls, as it would add a test for "am I overridden" that would generally take the "overridden" branch; perhaps we could detect classes with subclasses in the same AST and suppress inlining for this case. Similarly, it could spot the def override_me(self): raise NotImplementedError pattern and not try to inline. Other issues: - Somehow need to tie together symbol tables with ast2mod. One approach: do the symtable generation first, then adjust ast2mod so that it adds PySymtableEntry references to the generated python tree as appopriate. This would expose the name scope structure. But after the tree changes, do we need to regenerate the symbol table? Or we could annotate the python ast.Name objects with scope information, and the ast optimizer would be responsible for keeping this correct. The compiler could then rerun the symtable analysis on the returned AST, or could trust the optimizer's info. - What to do with the "locals()" builtin? Inlined functions could save a copy of locals with duplicate names, keeping their existing names for the locals in the inlined copy. This would lead to "locals()" having additional items when called from an inlined function. - Many optimizations would have to assume that locals don't change value. Can we assume that in an optimized build that it's acceptable that code that use the inspect module and manipulates the f_locals of a frame may have surprising behavior in the face of optimization? (e.g. I'd like to be able to optimize away locals if we can prove that absence of side-effects). - PyAST_obj2mod enforces checking for a particular top-level element. To cope with this, I needed to pass this around in a few places, so I introduced "enum PyCompilationMode" to avoid having the magic 0, 1, or 2 to designate the grammar variant. This better distinguishes these values from other places which use the ID of the start token: semantically equivalent, but with different constants. I haven't yet fixed this up in Modules/parsermodule.c - Plenty of FIXMEs in the code, many of which are in themselves major issues - I'm not yet checking the optimization flag; that should probably be required to be on for this to be called. - Is "__optimizer__" a sane name? perhaps just "optimizer" - Too unstable to benchmark as yet. - There are probably other issues I haven't thought of yet. Notes: - the patch also contains a fix for issue 10391 (error handling is important when manipulating the AST) - potentially could add an optimize_cfg() hook, and expose the CFG struct basicblock and struct instr as Python objects in a similar way, as a later optimization pass Thanks to Red Hat for giving me time to experiment on this |
|||
| msg121076 - (view) | Author: Antoine Pitrou (pitrou) * |
Date: 2010-11-12 21:01 | |
<i>As I understand it, functions are "name-resolved" before the arguments are evaluated,</i> There is no difference between resolution of function names and of other names. For example, global names (LOAD_GLOBAL) are resolved entirely at runtime (just before the function gets called). The specialization issue means this would cooperate well with a globals cache (I've got a lingering patch for this, will post in a separate issue). |
|||
| msg121082 - (view) | Author: Antoine Pitrou (pitrou) * |
Date: 2010-11-12 21:30 | |
Globals cache patch posted on issue10401. |
|||
| msg121114 - (view) | Author: Alex Gaynor (alex) * |
Date: 2010-11-13 05:39 | |
Just a thought: it's possible to cover all the cases properly with inlining (locals, globals (even with cross module inlining), tracebacks, sys._getframe(), etc.), however I think you're going to find that manually managing all of those is going to quickly drive you up a tree if you want to also get meaningful speedups (from removing frame allocation, argument parsing, etc.). My 2¢. |
|||
| msg121151 - (view) | Author: Brett Cannon (brett.cannon) * |
Date: 2010-11-13 18:21 | |
While I have nothing to say directly about the inline optimization, I do have some stuff to say about moving to AST optimizations. First, doing in Python is a good thing. It not only makes prototyping easier, but it allows other VMs to use the optimizations w/o having to re-implement themselves. Second, the symtable pass does need to eventually get exposed (most likely as an optional pass one can do to an AST). I am actually in the middle of an AST-heavy project that will end up wanting the symbol table info as well. Third, for that Graphviz output, was anything special required? If so, I would toss the code into Tools for others to benefit from. |
|||
| msg121579 - (view) | Author: Dave Malcolm (dmalcolm) |
Date: 2010-11-20 00:01 | |
> Third, for that Graphviz output, was anything special required? If so, > I would toss the code into Tools for others to benefit from. It's merely the "to_dot" function from Lib/__optimizer__.py (which turns an AST into .dot source code), followed by "dot_to_png" in the same file which invokes /usr/bin/dot on it, which is likely to be readily available on any Linux system. Would it be reasonable to add "to_dot" to Lib/ast.py? (it's ~25 lines, and very similar to that file's "dump" function. |
|||
| msg121581 - (view) | Author: Brett Cannon (brett.cannon) * |
Date: 2010-11-20 00:12 | |
No, it's rather Linux and tool specific to go into ast.py. But adding it to the Tools/ directory makes sense. |
|||
| msg121585 - (view) | Author: Dave Malcolm (dmalcolm) |
Date: 2010-11-20 01:10 | |
Sorry again for another epic-length comment... I'm attaching the latest work-in-progress on this. The code is still fairly messy (embarrasingly so in places), but it's better to have it out in public in this tracker than stuck on my hard drive. Symbol tables ============= - I've moved the optimization pass to after symbol table generation. Pass the symtable to mod2obj et al, adding an "ste" attribute to all objects that have their own PySTEntryObject (adding a PySymtable_TryLookup function to Python/symtable.c to help with this). The symtable pass is rerun after optimization. - the "ste" attribute isn't exposed anywhere in the grammar (do other VMs implement symbol table entries?) - in the graphviz debug output, add boxes around scopes (i.e. those nodes with an "ste") - use the symbol table info: only inline functions that purely reference locals and globals, not free/cellvars. - only rename locals when inlining, not globals - don't inline functions that use the "locals" or "dir" builtin Specialization ============== I've implemented a first pass at the specialization ideas in the original comment. I've added a new AST node: "Specialize". It's an expression, but contains statements. -- Generated by the optimizer: | Specialize(expr name, stmt* specialized_body, expr specialized_result, expr generalized) -- must be a Call The idea is that: - "name" should be dynamically evaluated, then compared in some (not yet well specified) way against the expected value during inlining - If we have a match: - then execute the statements in "specialized_body", then evaluate "specialized_result", the latter giving the overall value of this expression - If we don't have a match: - then evaluate "generalized", which currently must be a Call, and this gives the overall value of the expression. I've added a JUMP_IF_SPECIALIZABLE opcode, mostly as described in the initial comment. This allows us to implement "specialized" bytecode that makes an assumption, but has a fallback ("generalized") for the case when the assumption fails. To wire this up for function inlining, we need some way of recording the "original" version of a function versus what it's now bound to. For now, I'm simply adding an assignment after each function def, equivalent to: def foo(): print('hello world') __saved__foo = foo def callsite(): foo() and the "Specialize" in "callsite" is compiled to: LOAD_GLOBAL (foo) ; dynamic lookup LOAD_GLOBAL (__saved__foo__) ; get saved version JUMP_IF_SPECIALIZABLE -> inline impl CALL_FUNCTION 0 POP_TOP JUMP_FORWARD ; inline implementation LOAD_GLOBAL ('print') LOAD_CONST ('hello world') CALL_FUNCTION 1 POP_TOP LOAD_CONST (None) RETURN_VALUE Additional optimizations ======================== I've added: - a very simple copy-propagation pass, which only runs on functions with a single basic block (to keep dataflow ananalysis simple: no edges in the CFG, since we don't have an explicit CFG yet) - a pass which removes locals that are only ever written to, never read from, provided that the function doesn't use "globals", "locals", or "dir" These combine nicely with the function inlining. For example, given this code (from "test_copy_propagation"):: def function_to_be_inlined(a, b, c, d): return(a + b + c + d) def callsite(): print(function_to_be_inlined('fee', 'fi', 'fo', 'fum')) then "callsite" compiles down to this bytecode:: 5 0 LOAD_GLOBAL 0 (print) 3 LOAD_GLOBAL 1 (function_to_be_inlined) 6 LOAD_GLOBAL 2 (__saved__function_to_be_inlined) 9 JUMP_IF_SPECIALIZABLE 30 12 LOAD_CONST 1 ('fee') 15 LOAD_CONST 2 ('fi') 18 LOAD_CONST 3 ('fo') 21 LOAD_CONST 4 ('fum') 24 CALL_FUNCTION 4 27 JUMP_FORWARD 15 (to 45) >> 30 LOAD_CONST 0 (None) 33 STORE_FAST 0 (__inline_function_to_be_inlined_1976300____returnval__) 36 LOAD_CONST 7 ('feefifofum') 39 STORE_FAST 0 (__inline_function_to_be_inlined_1976300____returnval__) 42 LOAD_FAST 0 (__inline_function_to_be_inlined_1976300____returnval__) >> 45 CALL_FUNCTION 1 48 POP_TOP 49 LOAD_CONST 0 (None) 52 RETURN_VALUE Note how the specialized inline implementation is able to do: LOAD_CONST 7 ('feefifofum') rather than have to compute the sum at runtime. (the return value handling is still a little messy, alas). Other stuff =========== - don't try to optimize anything until the end of Py_InitializeEx, since we can't run arbitrary python code until e.g. "sys" and "codecs" etc are brought up - don't inline for functions that have rebound names - co_lnotab's implementation of line numbers described in Objects/lnotab_notes.txt only supports monotonically-increasing line numbers within a code object's bytecode, but with inlining, we can jump around arbitrarily within one file. I've disabled the check for now, and line numbers sometimes come out wrong. Correctness =========== Just a proof-of-concept for now. There's a "safety switch" in Lib/__optimizer__.py:is_test_code which restricts optimizations to just a few places. I've been occasionally turning it off and runnning regrtest: many tests pass, many fail; I have fixed some failures as I see them. Performance =========== The optimizer is currently slow, and adds a noticable delay whey compiling a .py file. Potentially it could be optimized. Alternatively, we could gain a command-line flag to tell python to more heavily optimize its bytecode. This is particularly relevant with my downstream-distributor hat on: in Fedora and RHEL we ship hundreds of Python packages (and .pyc/.pyo) via RPM, and it would be simple to turn up the optimizations when we do a build. bm_call_simple.py gets significantly faster: a 49% speedup (albeit for a do-nothing benchmark, and this isn't counting the start-up time):: ### call_simple ### Min: 0.320839 -> 0.214237: 1.4976x faster Avg: 0.322125 -> 0.215405: 1.4954x faster Significant (t=155.641488) Stddev: 0.00246 -> 0.00099: 2.4894x smaller Timeline: b'http://tinyurl.com/2abok5l' Other benchmarks show no change, or slight slowdowns (or crashes). I hope that this will improve upon implementation method-call inlining. |
|||
| msg121586 - (view) | Author: Antoine Pitrou (pitrou) * |
Date: 2010-11-20 01:16 | |
> Sorry again for another epic-length comment... > > I'm attaching the latest work-in-progress on this. If this a work in progress, you could create an SVN branch in the sandbox (you can then use svnmerge to avoid diverging too much from mainline) or an hg repo. |
|||
| msg121597 - (view) | Author: Alex Gaynor (alex) * |
Date: 2010-11-20 09:08 | |
There are a couple places you mention not doing the optimization when specific functions are used (e.g. dir, globals, locals), how exactly do you verify that, given those functions could be bound to any name? |
|||
| msg121778 - (view) | Author: Dave Malcolm (dmalcolm) |
Date: 2010-11-20 21:11 | |
Thanks for reading through this.
> There are a couple places you mention not doing the optimization when
> specific functions are used (e.g. dir, globals, locals), how exactly do you
> verify that, given those functions could be bound to any name?
I don't: I'm only looking at explicit references to these global names:
BUILTINS_THAT_READ_LOCALS = {'locals', 'vars', 'dir'}
but I haven't attempted to track these at the object level, just at the name level.
This means that if someone is passing these around bound to a different name, the results could be "wrong": the optimizations that I'm doing are synthesizing new local and global variables (in each case with a '__' prefix), and sometimes eliminating local variables.
However, it should work as expected for the simple and common case for code like this:
def foo():
...
pprint(locals())
...
since the reference to "locals" can be seen at the name level.
But it won't work for something like this:
def inlined_fn(a):
print(a())
def not_inlinable_for_some_reason(b):
inlined_fn(b) # assume this callsite is inlined
def some_other_fn_perhaps_in_another_module():
hidden_ref_to_locals = locals
not_inlinable_for_some_reason(hidden_ref_to_locals)
in that (if inlining happens) the local printed will be named "b", rather than "a".
But this seems to me like a contrived example: how often in real code do people pass around these builtins, rather than calling them directly? I myself use them for debugging, but I only ever call them directly.
At a high level, what I'm interested in is providing additional benefits for python 3 relative to python 2 (to encourage migration), and I picked speed-ups.
I think it's reasonable to provide some kind of "optimized" mode that is allowed to take (limited) liberties with the language.
Note that with other languages, people seem to accept some mild degradation of debuggability in return for compiler optimizations. I'd like to be able to provide a faster python under similar kinds of tradeoffs.
Currently, Python's optimized mode doesn't seem to do much (just compile away assertions iirc). Perhaps these optimizations could be associated with the pre-existing optimizer flag; alternatively, perhaps a 3rd level could be provided?
This seems like a PEP-level request, but here's an outline of my thoughts here:
I'd like the highly-optimized mode to be permitted the following::
- to create additional synthesized globals, with a "__" prefix; modification of these globals to lead to undefined behavior.
- when querying locals under some circumstances (see below) for locals to not be present, or for additional locals to be present::
- when using "inspect" and reading/modifying a Frame's f_locals
- in "non-direct" invocations of "locals", "globals" and "dir" (however, when called directly by name, they must work)
- as per globals, synthesized locals to have a prefix, and modification to lead to undefined behavior
- a pony :)
- more seriously, I'm planning to look next at inlining method calls (within one module), and type inference, and I may come up with additional requirements.
I believe that the above covers all of the places where my patch is taking liberties with existing Python semantics (modulo bugs): I'm still supporting runtime rebinding of other names, and (I believe), preserving existing behavior. (please let me know if I'm missing something here!)
There seems to be some precedent for this:
http://docs.python.org/library/functions.html states:
> Note Because dir() is supplied primarily as a convenience for use at an
> interactive prompt, it tries to supply an interesting set of names more
> than it tries to supply a rigorously or consistently defined set of names,
> and its detailed behavior may change across releases. For example,
> metaclass attributes are not in the result list when the argument is a class.
and for locals() it warns:
> Note The contents of this dictionary should not be modified; changes may not
> affect the values of local and free variables used by the interpreter.
Does this sound sane? (obviously, actually approving this would be a matter for the BDFL).
Perhaps all synthesized vars could have a "__internal__" prefix to signify that they should be left alone.
The other PEP-level request would be for the highly-optimized mode to be permitted to take human-noticable time to generate its bytecode (rather than being "instantaneous"). I don't know if that's needed yet: the inliner is currently just a prototype, and I don't have any heuristics yet for deciding whether to inline a callsite (beyond an arbitrary cutoff I put in to stop bm_simple_call from "exploding"); I'm probably introducing various O(N^2) time/space behaviors (and worse) right now.
|
|||
| msg121786 - (view) | Author: Neal Norwitz (nnorwitz) * |
Date: 2010-11-20 21:35 | |
There is some precedent for allowing minor differences in -O mode. http://mail.python.org/pipermail/python-dev/2008-February/077193.html I think we should push this to see how practical we can make it. Dave, this is great work, I'm really interested to see you continue to make progress and get something integrated. Keep up the good work. On Sat, Nov 20, 2010 at 1:11 PM, Dave Malcolm <report@bugs.python.org> wrote: > > Dave Malcolm <dmalcolm@redhat.com> added the comment: > > Thanks for reading through this. > >> There are a couple places you mention not doing the optimization when >> specific functions are used (e.g. dir, globals, locals), how exactly do you >> verify that, given those functions could be bound to any name? > > I don't: I'm only looking at explicit references to these global names: > BUILTINS_THAT_READ_LOCALS = {'locals', 'vars', 'dir'} > > but I haven't attempted to track these at the object level, just at the name level. > > This means that if someone is passing these around bound to a different name, the results could be "wrong": the optimizations that I'm doing are synthesizing new local and global variables (in each case with a '__' prefix), and sometimes eliminating local variables. > > However, it should work as expected for the simple and common case for code like this: > > def foo(): > ... > pprint(locals()) > ... > > since the reference to "locals" can be seen at the name level. > > But it won't work for something like this: > > def inlined_fn(a): > print(a()) > > def not_inlinable_for_some_reason(b): > inlined_fn(b) # assume this callsite is inlined > > def some_other_fn_perhaps_in_another_module(): > hidden_ref_to_locals = locals > not_inlinable_for_some_reason(hidden_ref_to_locals) > > in that (if inlining happens) the local printed will be named "b", rather than "a". > > But this seems to me like a contrived example: how often in real code do people pass around these builtins, rather than calling them directly? I myself use them for debugging, but I only ever call them directly. > > At a high level, what I'm interested in is providing additional benefits for python 3 relative to python 2 (to encourage migration), and I picked speed-ups. > > I think it's reasonable to provide some kind of "optimized" mode that is allowed to take (limited) liberties with the language. > > Note that with other languages, people seem to accept some mild degradation of debuggability in return for compiler optimizations. I'd like to be able to provide a faster python under similar kinds of tradeoffs. > > Currently, Python's optimized mode doesn't seem to do much (just compile away assertions iirc). Perhaps these optimizations could be associated with the pre-existing optimizer flag; alternatively, perhaps a 3rd level could be provided? > > This seems like a PEP-level request, but here's an outline of my thoughts here: > > I'd like the highly-optimized mode to be permitted the following:: > - to create additional synthesized globals, with a "__" prefix; modification of these globals to lead to undefined behavior. > - when querying locals under some circumstances (see below) for locals to not be present, or for additional locals to be present:: > - when using "inspect" and reading/modifying a Frame's f_locals > - in "non-direct" invocations of "locals", "globals" and "dir" (however, when called directly by name, they must work) > - as per globals, synthesized locals to have a prefix, and modification to lead to undefined behavior > - a pony :) > - more seriously, I'm planning to look next at inlining method calls (within one module), and type inference, and I may come up with additional requirements. > > I believe that the above covers all of the places where my patch is taking liberties with existing Python semantics (modulo bugs): I'm still supporting runtime rebinding of other names, and (I believe), preserving existing behavior. (please let me know if I'm missing something here!) > > There seems to be some precedent for this: > http://docs.python.org/library/functions.html states: >> Note Because dir() is supplied primarily as a convenience for use at an >> interactive prompt, it tries to supply an interesting set of names more >> than it tries to supply a rigorously or consistently defined set of names, >> and its detailed behavior may change across releases. For example, >> metaclass attributes are not in the result list when the argument is a class. > > and for locals() it warns: >> Note The contents of this dictionary should not be modified; changes may not >> affect the values of local and free variables used by the interpreter. > > Does this sound sane? (obviously, actually approving this would be a matter for the BDFL). > > Perhaps all synthesized vars could have a "__internal__" prefix to signify that they should be left alone. > > > The other PEP-level request would be for the highly-optimized mode to be permitted to take human-noticable time to generate its bytecode (rather than being "instantaneous"). I don't know if that's needed yet: the inliner is currently just a prototype, and I don't have any heuristics yet for deciding whether to inline a callsite (beyond an arbitrary cutoff I put in to stop bm_simple_call from "exploding"); I'm probably introducing various O(N^2) time/space behaviors (and worse) right now. > > ---------- > > _______________________________________ > Python tracker <report@bugs.python.org> > <http://bugs.python.org/issue10399> > _______________________________________ > |
|||
| msg122233 - (view) | Author: Dave Malcolm (dmalcolm) |
Date: 2010-11-23 18:57 | |
> If this a work in progress, you could create an SVN branch in the > sandbox (you can then use svnmerge to avoid diverging too much from > mainline) or an hg repo. Good idea; I've created branch "dmalcolm-ast-optimization-branch" (of py3k) on svn.python.org for use as I build up my prototype implementation of this. |
|||
| msg122237 - (view) | Author: Dave Malcolm (dmalcolm) |
Date: 2010-11-23 19:27 | |
py3k-ast-pyoptimize-2010-11-19-006.patch fixed up and committed to the branch as r86715; I'll work on that branch for the time being. |
|||
| msg122344 - (view) | Author: Armin Rigo (arigo) * |
Date: 2010-11-25 08:53 | |
> But this seems to me like a contrived example: how often in real > code do people pass around these builtins, rather than calling > them directly? From experience developing PyPy, every argument that goes "this theoretically breaks obscure code, but who writes it in that way?" is inherently broken: there *is* code out there that uses any and all Python strangenesses. The only trade-offs you can make is in how much existing code you are going to break -- or make absolutely sure that you don't change semantics in any case. |
|||
| msg245630 - (view) | Author: Mark Lawrence (BreamoreBoy) * | Date: 2015-06-22 14:23 | |
I get the impression that there's a lot to be gained here, especially when compared to some of the micro-optimizations that are committed. Can we resurrect this, perhaps by taking it up on python-dev? Also msg121082 refers to a Globals cache patch posted on issue10401. |
|||
| msg255516 - (view) | Author: STINNER Victor (vstinner) * |
Date: 2015-11-28 01:28 | |
"Can we resurrect this, perhaps by taking it up on python-dev?" I created a new "FAT Python" project to reimplement such kind of optimizations with a similar design (similar but different ;-)): https://faster-cpython.readthedocs.org/fat_python.html |
|||
| History | |||
|---|---|---|---|
| Date | User | Action | Args |
| 2022-04-11 14:57:08 | admin | set | github: 54608 |
| 2020-11-19 01:06:26 | phsilva | set | nosy:
+ phsilva |
| 2020-08-20 13:32:21 | BTaskaya | set | nosy:
+ BTaskaya |
| 2020-08-12 01:05:26 | Yonatan Goldschmidt | set | nosy:
+ Yonatan Goldschmidt |
| 2017-03-15 06:45:50 | mbdevpl | set | nosy:
+ mbdevpl |
| 2017-01-29 14:45:25 | BreamoreBoy | set | nosy:
- BreamoreBoy |
| 2017-01-29 11:35:57 | THRlWiTi | set | nosy:
+ THRlWiTi |
| 2015-11-28 01:28:13 | vstinner | set | nosy:
+ vstinner messages: + msg255516 |
| 2015-06-22 14:23:02 | BreamoreBoy | set | nosy:
+ BreamoreBoy messages: + msg245630 versions: + Python 3.6, - Python 3.3 |
| 2013-01-11 17:11:50 | brett.cannon | set | nosy:
- brett.cannon |
| 2012-07-24 10:06:51 | ncoghlan | set | nosy:
+ ncoghlan |
| 2012-07-24 05:59:34 | eric.snow | set | nosy:
+ eric.snow |
| 2012-07-19 04:55:28 | gregory.p.smith | set | nosy:
+ gregory.p.smith |
| 2012-07-18 11:17:53 | giampaolo.rodola | set | nosy:
+ giampaolo.rodola |
| 2011-10-09 01:54:44 | meador.inge | set | nosy:
+ meador.inge |
| 2011-06-01 02:24:49 | jcon | set | nosy:
+ jcon |
| 2011-05-05 18:01:38 | pas | set | nosy:
+ pas |
| 2011-04-13 16:29:48 | arigo | set | nosy:
- arigo |
| 2011-04-13 03:17:51 | rfk | set | nosy:
+ rfk |
| 2010-12-08 22:42:03 | dmalcolm | set | assignee: dmalcolm |
| 2010-11-25 09:49:43 | fijall | set | nosy:
+ fijall |
| 2010-11-25 08:53:51 | arigo | set | nosy:
+ arigo messages: + msg122344 |
| 2010-11-23 19:27:07 | dmalcolm | set | messages: + msg122237 |
| 2010-11-23 18:57:11 | dmalcolm | set | messages: + msg122233 |
| 2010-11-20 21:35:25 | nnorwitz | set | messages: + msg121786 |
| 2010-11-20 21:11:18 | dmalcolm | set | messages: + msg121778 |
| 2010-11-20 09:08:28 | alex | set | messages: + msg121597 |
| 2010-11-20 01:16:00 | pitrou | set | messages: + msg121586 |
| 2010-11-20 01:10:41 | dmalcolm | set | files:
+ py3k-ast-pyoptimize-2010-11-19-006.patch messages: + msg121585 |
| 2010-11-20 00:12:47 | brett.cannon | set | messages: + msg121581 |
| 2010-11-20 00:01:36 | dmalcolm | set | messages: + msg121579 |
| 2010-11-16 08:58:02 | orsenthil | set | nosy:
+ orsenthil |
| 2010-11-13 18:21:54 | brett.cannon | set | nosy:
+ brett.cannon messages: + msg121151 |
| 2010-11-13 05:39:26 | alex | set | messages: + msg121114 |
| 2010-11-12 21:30:14 | pitrou | set | messages: + msg121082 |
| 2010-11-12 21:01:30 | pitrou | set | nosy:
+ pitrou messages: + msg121076 |
| 2010-11-12 20:18:58 | dmalcolm | set | files: + after.png |
| 2010-11-12 20:18:28 | dmalcolm | set | files: + before.png |
| 2010-11-12 20:16:50 | dmalcolm | create | |